Apache Spark
Apache Spark is an open-source unified analytics engine for large-scale data processing. Used it for Aquantix AI.
What is Spark?
Efficient
- General execution graphs
- In-memory storage
Usable
- Rich APIs in Java, Scala, Python
- Interactive shell
Broadcast variables:
Spark is lazy evaluated
This helps Spark to optimize the execution and load only the data that is really needed for evaluation.
First, understand how an RDD works.
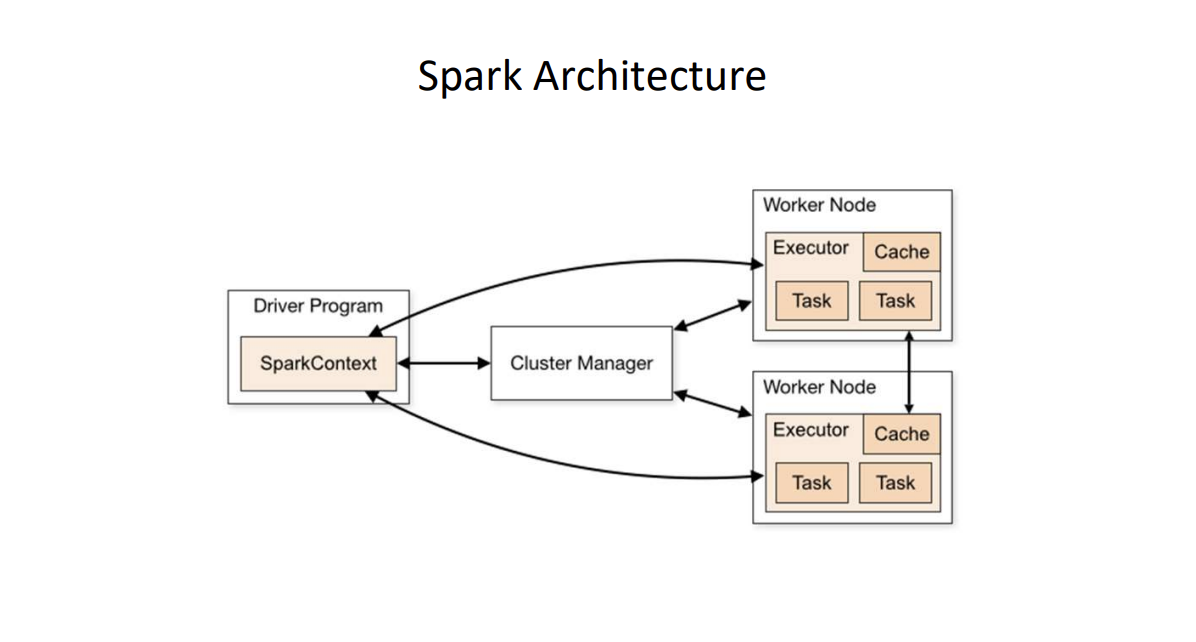
Spark Context
SparkContext
- Main entry point to Spark functionality
- Available in shell as variable
sc - In standalone programs, you’d make your own
val sc = new SparkContext(conf)Map and Reduce Operations
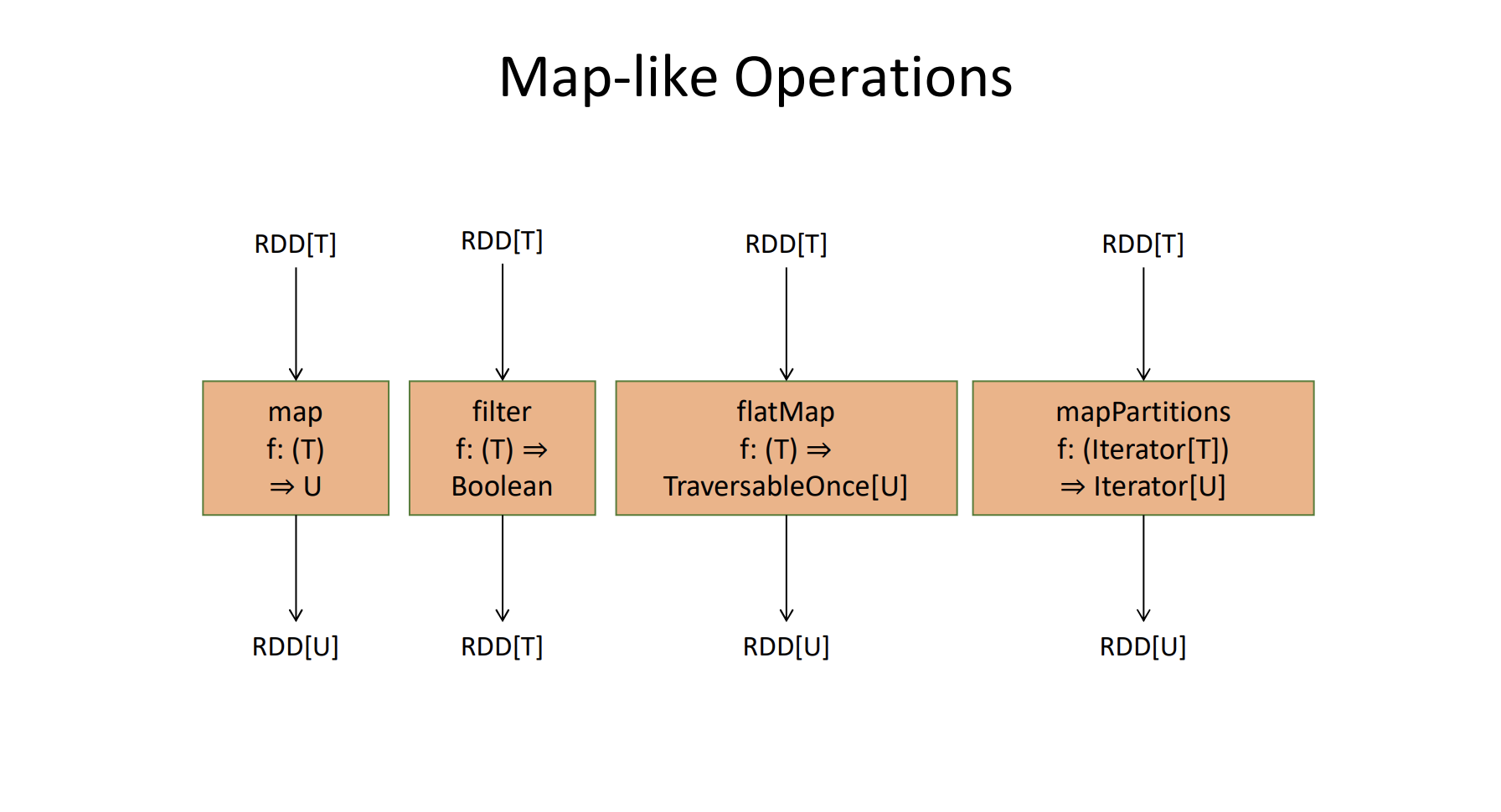
Consider an RDD[T] with 4 partitions on 4 workers. The above operations return an RDD[U] with 4 partitions.
Let’s call the RDD[T] as RDD_in and the returned RDD[U] as RDDout:
map(f) – f is given one value of type T, and returns one value of type U
- Each worker will call f(x) on each item x from RDDin
- Each worker will put the value returned by f(x) into a partition of RDDout
flatMap(f)– f is given one value of type T, and returns an iterator/iterable collection that produces values of type U - Each worker will call f(x) on each item x from RDDin
- Each worker will then traverse the iterable returned by f(x), and each value gets added to RDDout (see flatMap (Scala))
- (If you think only in terms of lists, then instead of getting an RDD of lists, they are “flattened”)
mapPartitions(f)– f is given an iterator that produces value of type T, and returns an iterator/iterable collection that produces values of type U - Each worker will call f(x) ONCE where x is an iterator that traverses all items in that worker’s partition of RDDin
- Each worker will then traverse the iterable returned by f(x), and each value gets added to RDDout just like flatMap
- mapPartitions is handy when you want something like MapReduce’s setup and cleanup
i.e. you would do
def myFunction(values):
setup things
for x in values:
something, probably accumulating values
cleanup that returns accumulated values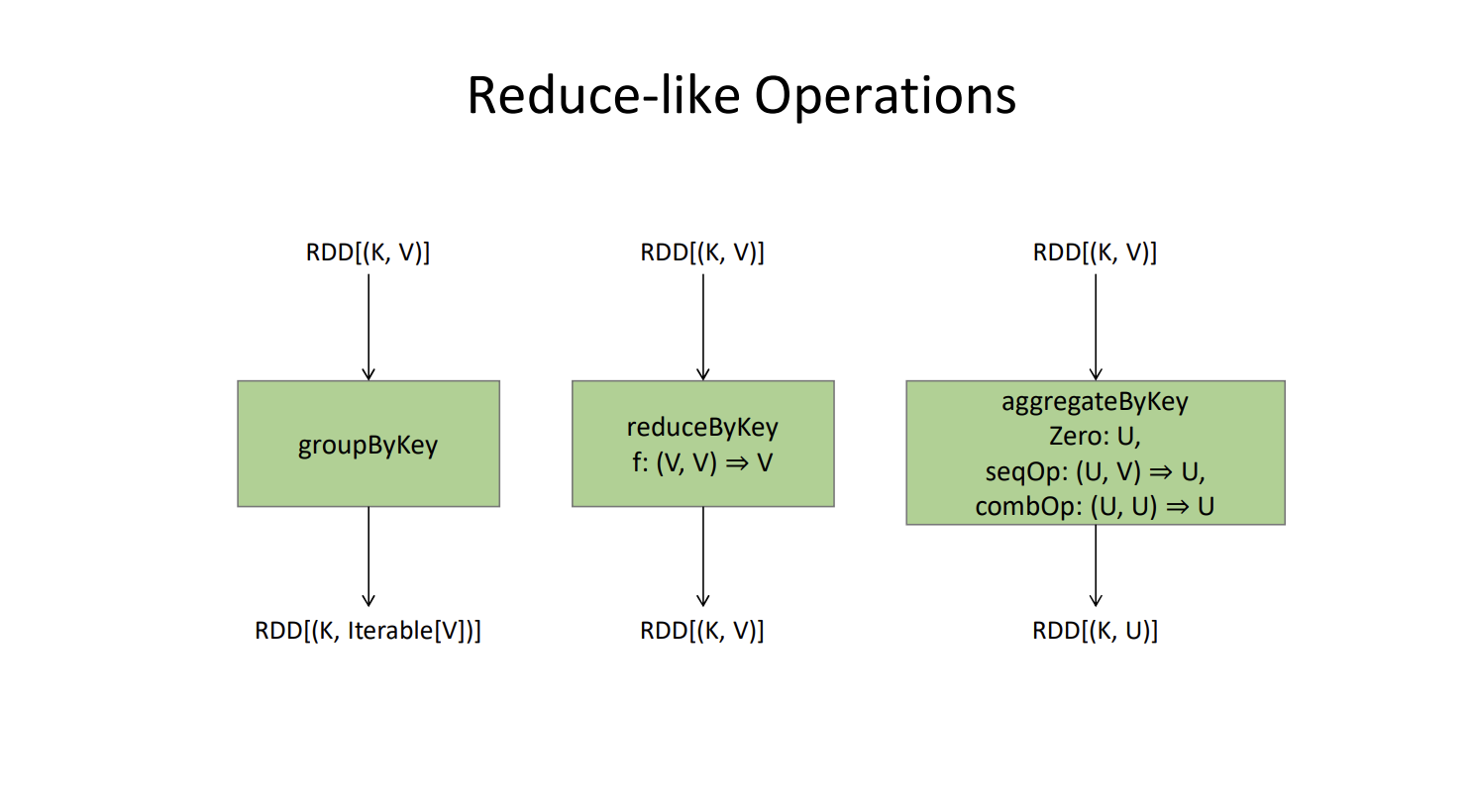
Note that these do NOT sort, they use in-memory hash tables for the shuffle, not sorted files. (Spark’s design assumes a lot more RAM than MapReduce does)
groupByKey – like MapReduces shuffle. NOT the reduce part, this is JUST the shuffle that brings the pairs to a single place. You’d then use map, flatMap, etc. to perform the reduce action itself.
reduceByKey – like MapReduce’s shuffle + combine + reduce.
What does a worker do to perform reduceByKey(f(a,b)) ?
- Create a Hash table called
HT - For each (K,V) pair in :
- If is not a key in , associate with in .
- Otherwise, retrieve the old value from , and replace it with
- Perform a shuffle – each reducer-like-worker will receive key-value pairs. It will then repeat step 2 for all received pairs.
Also see RDD for examples.
reduceByKey (Spark)vs.reduce(MapReduce)?Spark’s reduceByKey is NOT like the Reduce phase of MapReduce!
- reduceByKey – partitions the RDD, then reduces each partition, THEN shuffles for a final reduce

- So reduceByKey is a combiner + reducer
An example of reduceByKey
val data = sc.parallelize(Seq(("a", 1), ("b", 2), ("a", 3), ("b", 4)))
data.reduceByKey(_ + _) // Array(("a", 4), ("b", 6))Under the hood, reduceByKey(_ + _):
- Groups the values by their keys:
("a", [1, 3]), ("b", [2, 4]) - Sums the values for each key:
("a", 1 + 3) -> ("a", 4), ("b", 2 + 4) -> ("b", 6)
aggregateByKey – a more complicated reduceByKey
aggregateByKey(zero, insert, merge)
- Create a Hash table called HT
- For each (K,V) pair in RDDin:
- If k is not a key in HT, associate k with insert(zero, v) in HT.
- Otherwise, retrieve the accumulator u from HT, and replace it with insert(u,v)
- Perform a shuffle – each reducer-like-worker will receive key-value pairs.
The third parameter, merge, is used to combine accumulators.
(There’s also combineByKey which is the same, except instead of a zero-value, you give it another function, one that creates an accumulator out of a single value V.
Technically combineByKey is the only “real” function – aggregateByKey(zero, insert, merge) calls combineByKey(lambda v: insert(zero, v), insert, merge), and reduceByKey(f) calls combineByKey(identity,f,f).
Spark vs. Hadoop?
Since spark avoids heavy disk i/o, it significantly improves the performance.
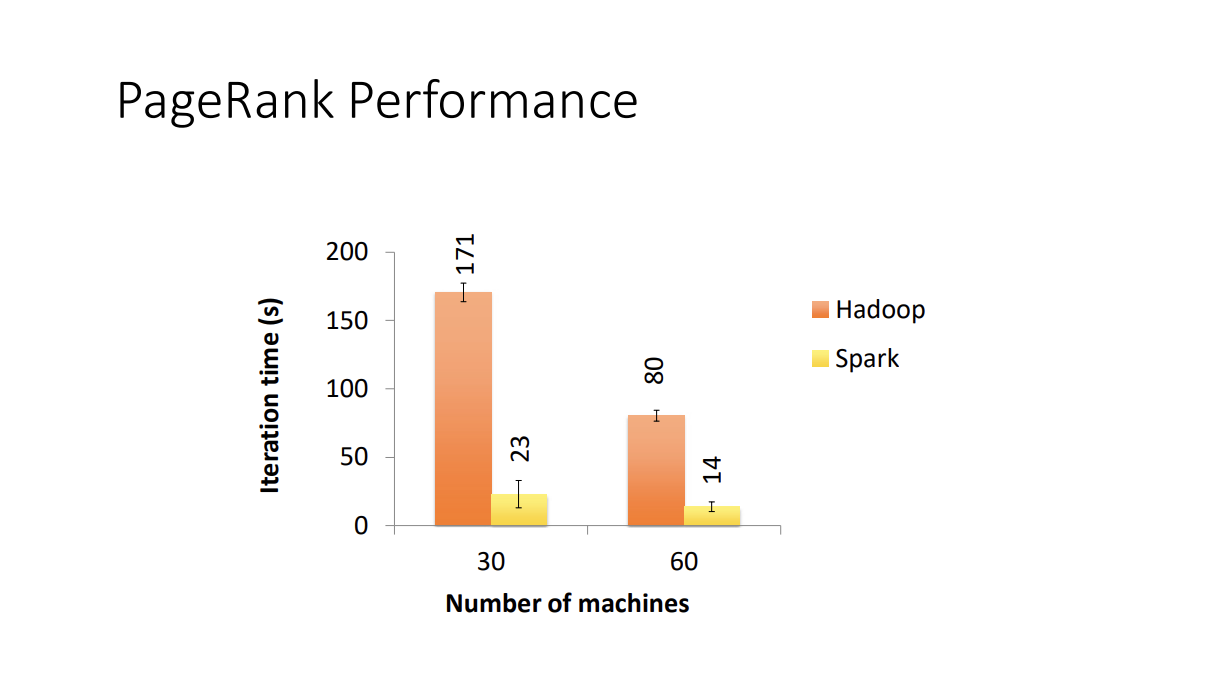
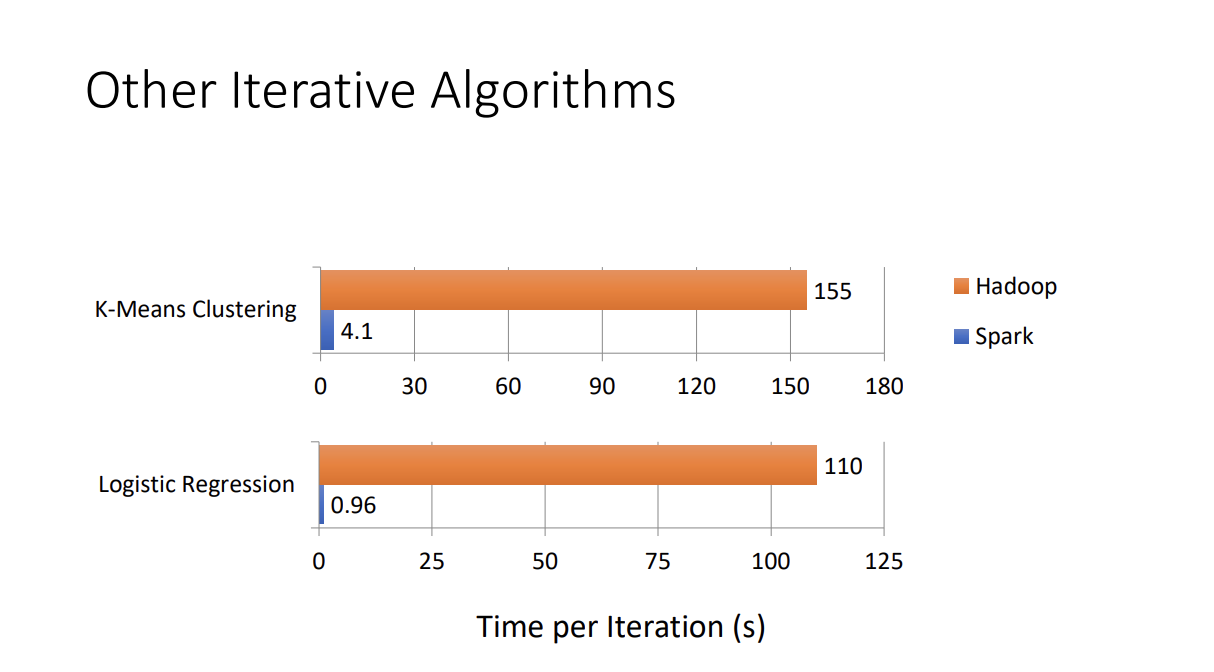
Spark outperforms Hadoop in iterative programs because it tries to keep the data that will be used again in the next iteration in memory. In contrast with Hadoop which always read and write from/to disk.
Broadcasting
I mean I’ve heard of broadcasting from NumPy, but I don’t think this is what it means.
If you Broadcast a value, then Spark only sends one copy per Executor (worker machine) not per Task.
- Ahh, refer to the diagram
thresh = sc.broadcast(5)
myRdd.filter(lambda x: x > thresh.value)IMPORTANT: Broadcast variables are read-only.
What is a task??
A task is the smallest unit of work in Spark. It represents a piece of computation that operates on a small chunk of data.
Types: Tasks can be either shuffle tasks (involving data shuffling between nodes) or result tasks (producing the final output).
Lifecycle:
- A Spark job is divided into multiple stages.
- Each stage is broken into tasks.
- Tasks are distributed to worker nodes for execution.
Accumulators
A Broadcast variable carries information from Driver to Executor.
What if we want communication from Executor back to Driver? Use an Accumulator!!
lineCounter = sc.accumulator(0)
def split_and_count(line):
lineCounter.add(1)
return line.split()
myRdd.map(split_and_count). …
lineCounter.value()val lineCounter = sc.longAccumulator
def split_and_count(line : String) = {
lineCounter.add(1)
line.split()
}
myRdd.map(split_and_count) ...
lineCounter.valueMore advanced things
Consider this CSV file with fields:
- User ID (unique key per user)
- Movie ID (unique key per movie)
- Rating (1-5 stars)
- Text of review (optional)
e.g. “1, 100, 3.5, ‘s aight”
We want to get the average rating per movie. How?
An initial idea is to do something like this:
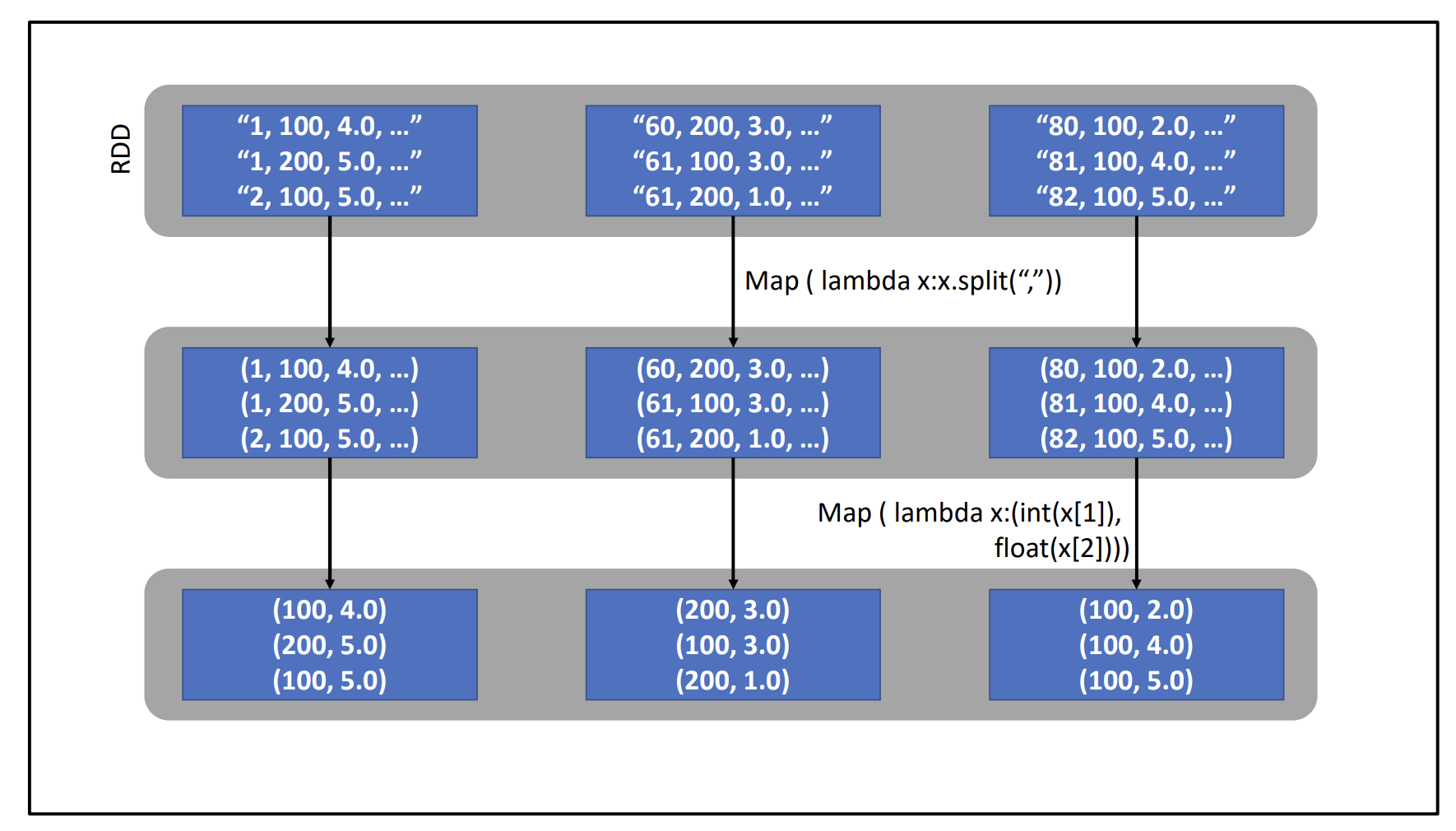
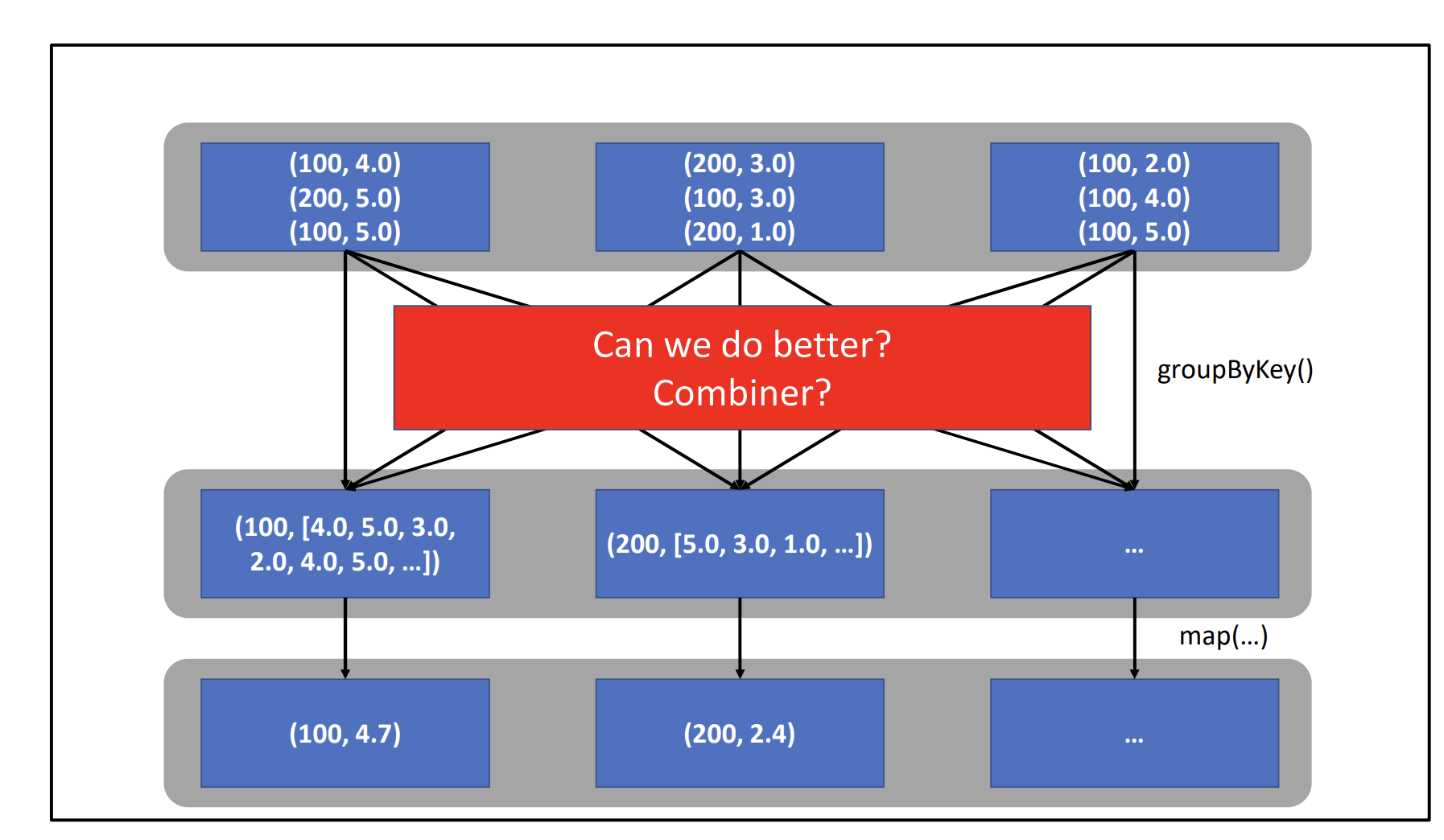
- We first
groupByKey, and then map (this is what we are familiar with when we did MapReduce).
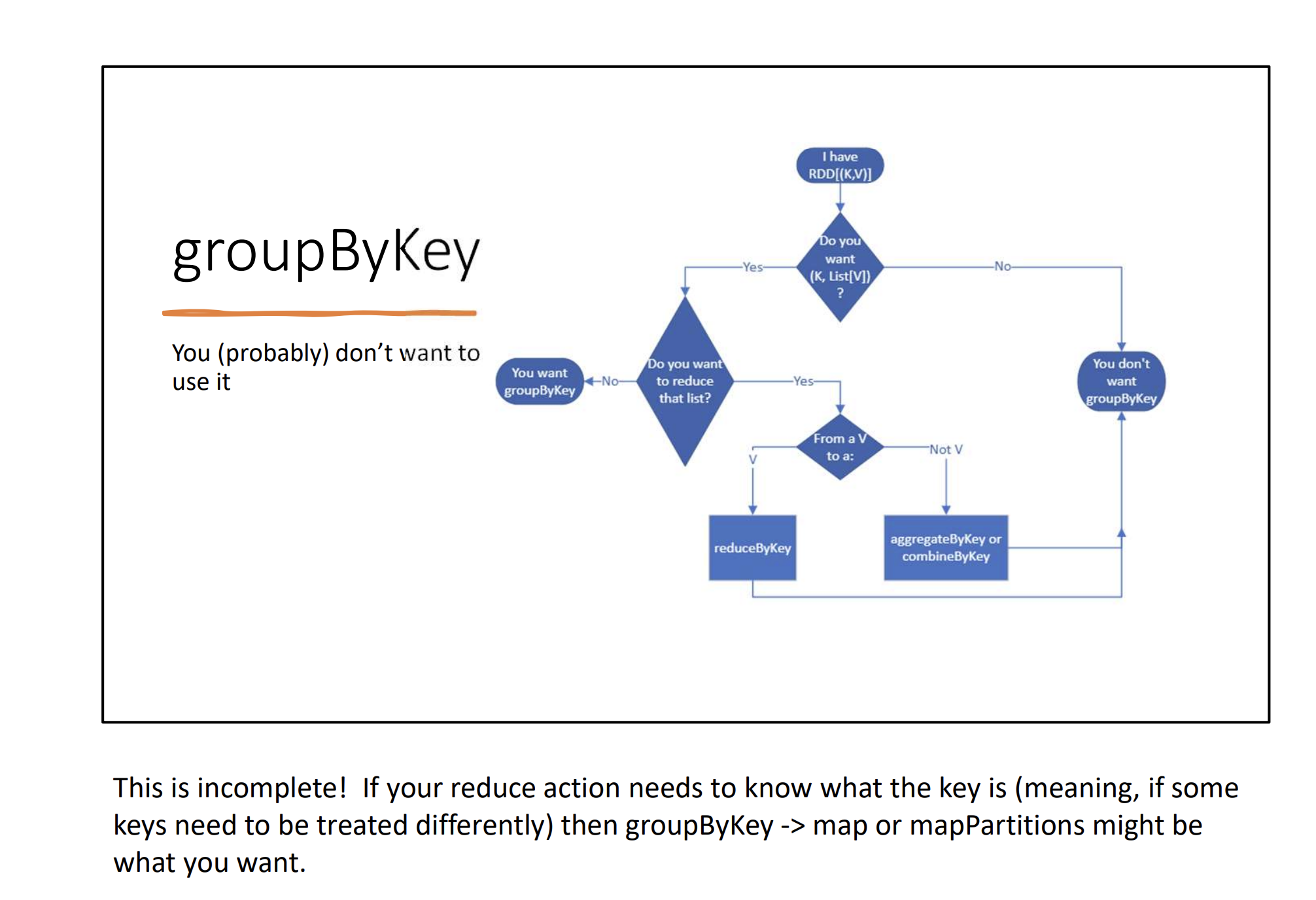
Avoid groupByKey if you can – MapReduce (without combiner) in Spark is essentially – flatmap → groupByKey → flatmap. We’re trying to do better than MapReduce though.
Instead of
rdd.flatMap(...).groupByKey().map(...)You can do
rdd.flatMap(...).reduceByKey(...).map(...)ReduceByKey avoids the inefficiencies of groupByKey by combining data before shuffling.
However, there’s a better way, because groupByKey is slow.
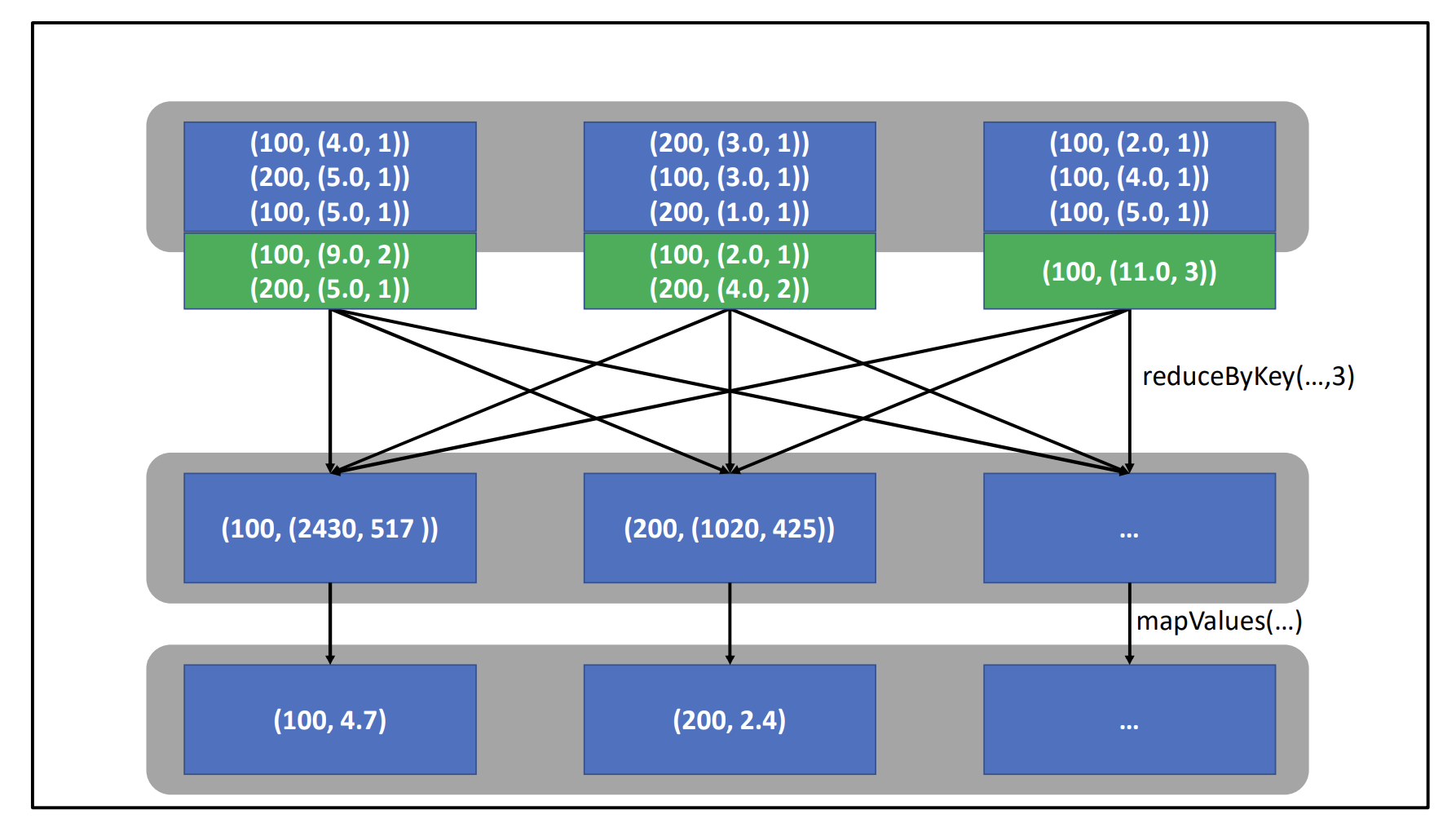
Scala
sc.textFile("movies.csv")
.map(_.split(",")).
.map(lst => (lst(1).toInt, (lst(2).toDouble,1))) // (movieID, (rating, 1))
.reduceByKey({case ((s1,c1), (s2,c2)) => (s1 + s2, c1 + c2)})
.mapValues({case (sum, cnt) => sum / cnt })
.coalesce(1)
.saveAsTextFile("averages")- This is initially confusing, but remember that
reduceByKeytakes two values with the same key and applies a function on both values
Python
sc.textFile("movies.csv").\
map(lambda line: line.split(",")).\
map(lambda lst:
(int(lst[1]), (float(lst[2]),1))).\
reduceByKey(lambda p1, p2:
(p1[0] + p2[0], p1[1] + p2[1])).\
mapValues(lambda pair: pair[0] / pair[1])).\
coalesce(1).\
saveAsTextFile("averages")Things
groupbykey, reducebykey, accumulatebykey
I’m kind of confused at the difference?!?!?
Sidenote on KV pairs
Spark’s “distributed reduce” transformations operate on RDDs of key-value pairs. How to index into those pairs?
Python:
pair = (a, b)
pair[0] # => a
pair[1] # => bScala:
val pair = (a, b)
pair._1 // => a
pair._2 // => bJava:
Tuple2 pair = new Tuple2(a, b)
pair._1 // => a
pair._2 // => b