SARSA
SARSA is the implementation of On-Policy TD Control. Off-policy implementation of TD Control is Q-Learning.
It is very similar to the idea we do with Monte-Carlo Control, (replace policy evaluation with TD-Learning, use the same policy improvement method with epsilon greedy).
Pseudocode

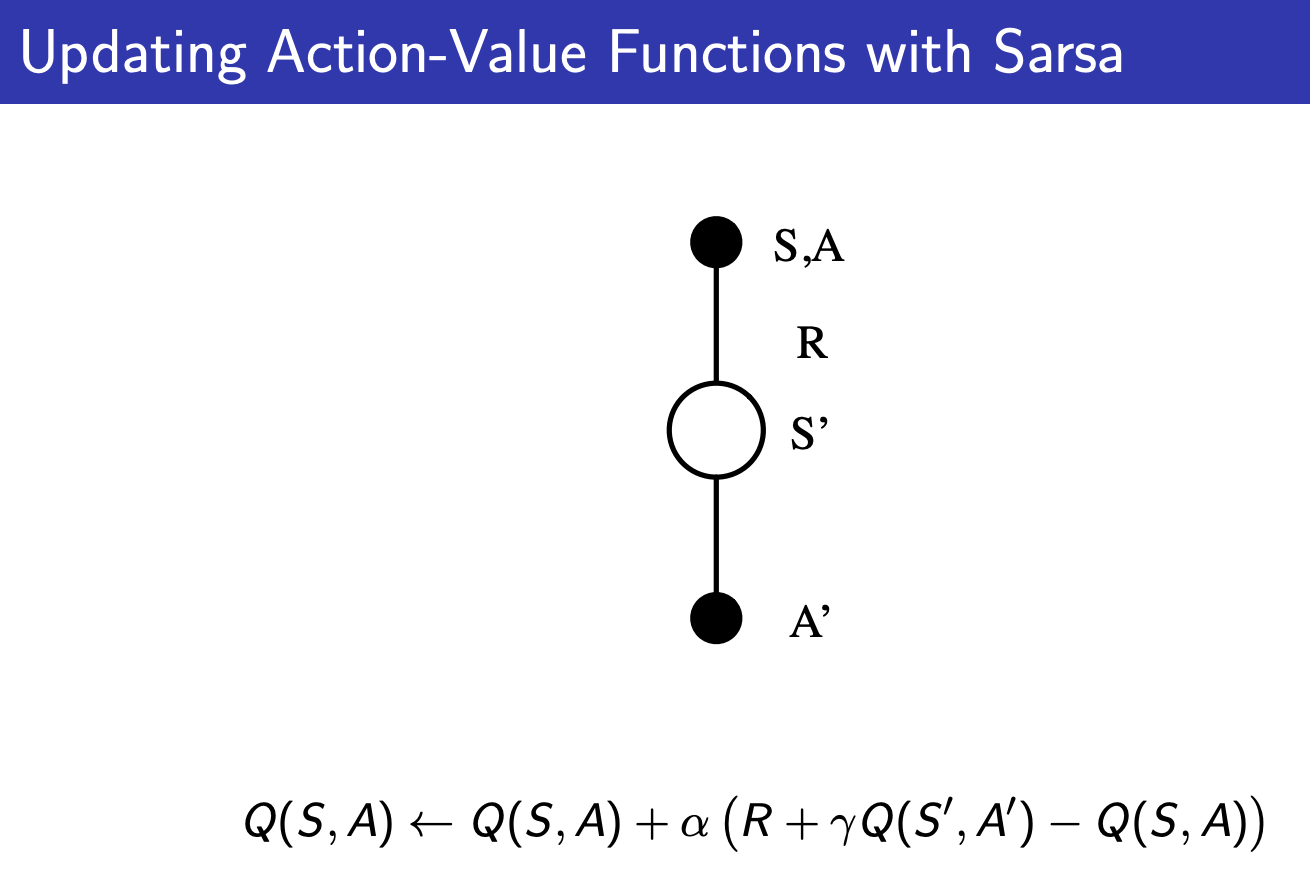
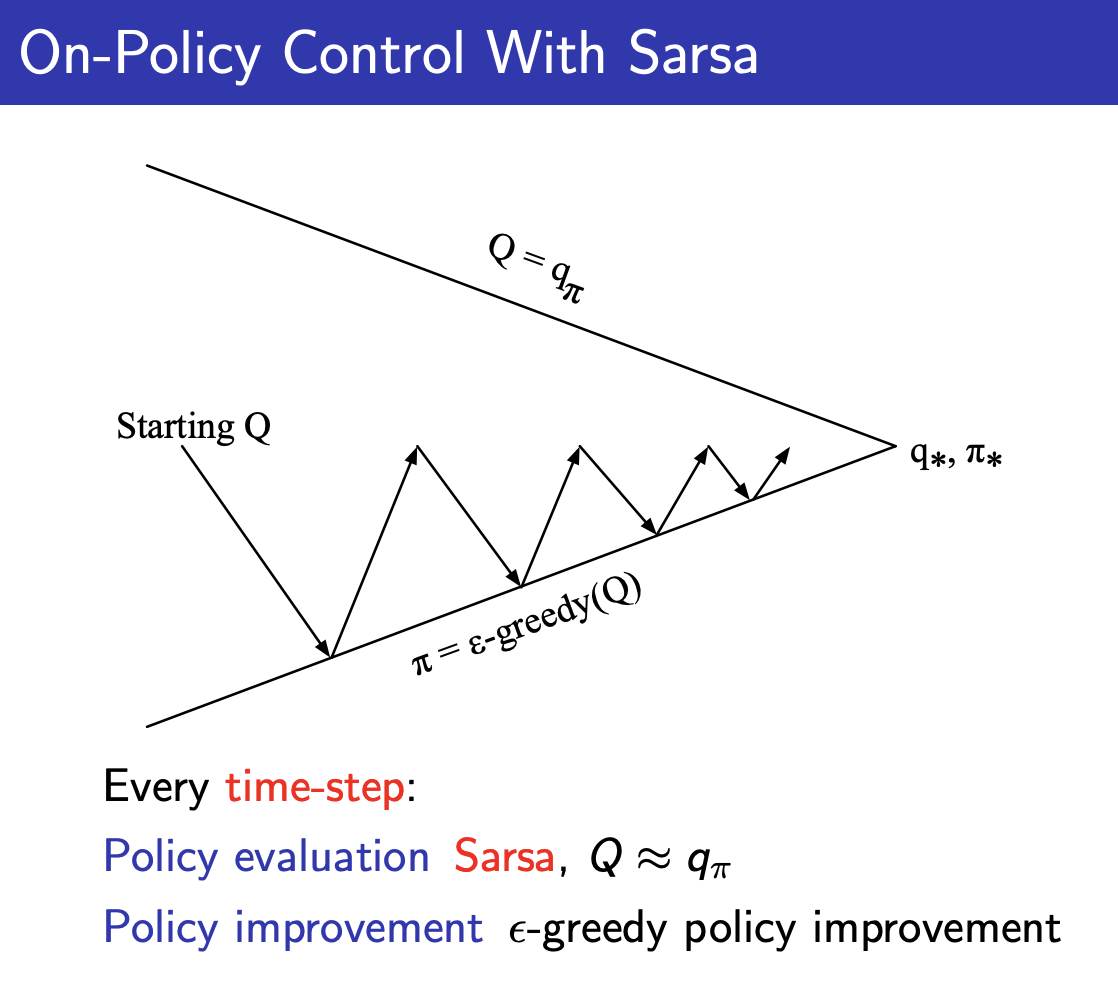
Convergence of Sarsa Theorem
Sarsa converges to the optimal action-value function, under the follow conditions:
- GLIE sequence of policies
- Robbins-Monro sequence of step-sizes
In practice, we don’t worry about this.
How does SARSA actually converge?
Like if you start from a very shitty policy, SARSA is just going to learn , not , so how are you going to get a good policy?
- The answer lies in the Policy Improvement image above, Generalized Policy Iteration
Sarsa ()
I guess there’s a Sarsa () version similar to how there’s a TD-Lambda version.