DeepMimic: Example-Guided Deep Reinforcement Learning of Physics-Based Character Skills
Core idea: “Minimize tracking error”
Very FUNDAMENTAL paper, really set the path for making locomation work.
- Limitation is that it’s a single-motion policy, later papers (and currently) we try to address this
Mentioned from BeyondMimic.
DeepMimic project page:
Blog https://bair.berkeley.edu/blog/2018/04/10/virtual-stuntman/
Where did they get the mocap from?
“Each skill is learned from approximately 0.5-5s of mocap data collected from http://mocap.cs.cmu.edu and http://mocap.cs.sfu.ca.”
The rewards:
- And the gains are slightly tuned
Is there normalization applied to those rewards?
Where each reward is something along the lines of
Some insights (mostly came from blog):
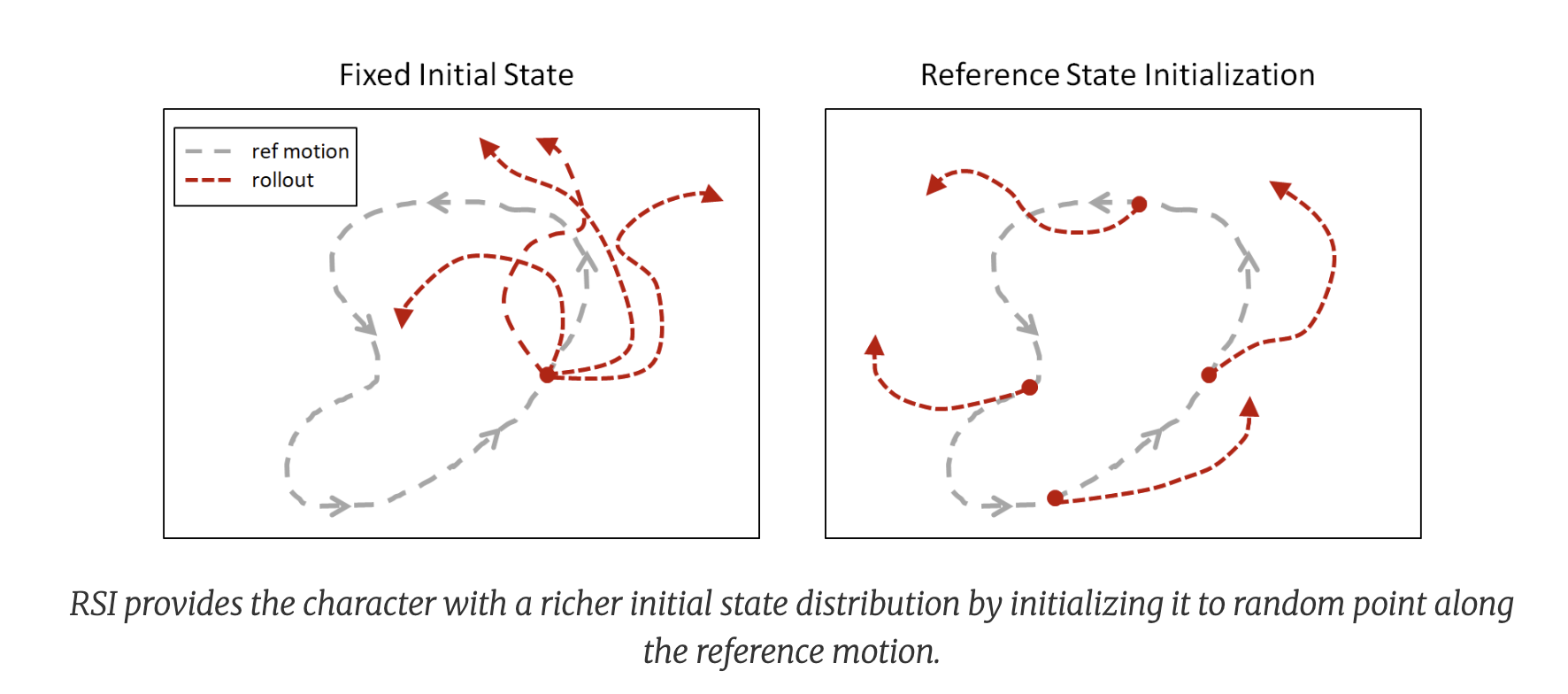
- Reference state initialization is very important to get it to work
- Early termination
- ” This is analogous to the class imbalance problem encountered by other methodologies such as supervised learning.”