Diffusion Policy
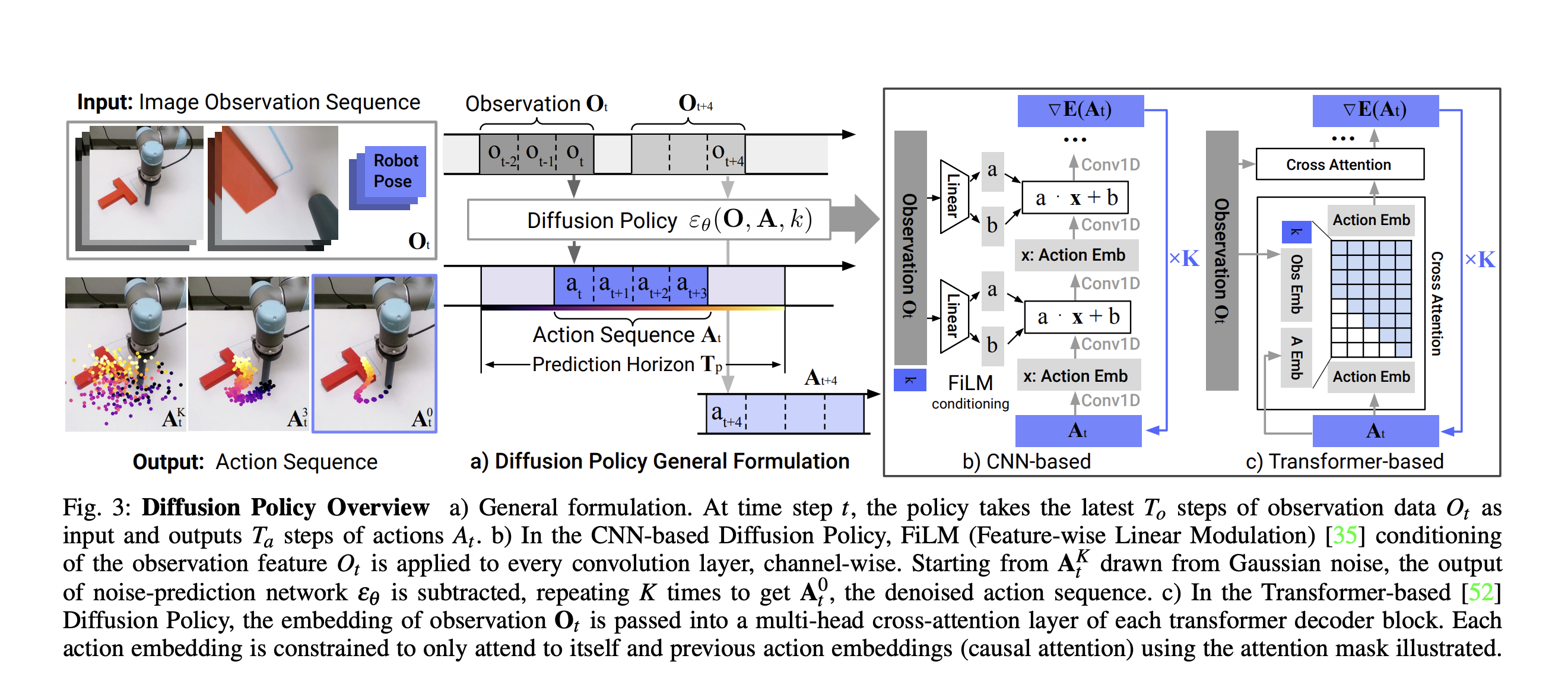
Diffusion policy presents a novel method for generating robot behavior by representing visuomotor policies as conditional denoising diffusion processes.
Advantages:
- handling multimodal action distributions
- suitability for high-dimensional action spaces
- stable training
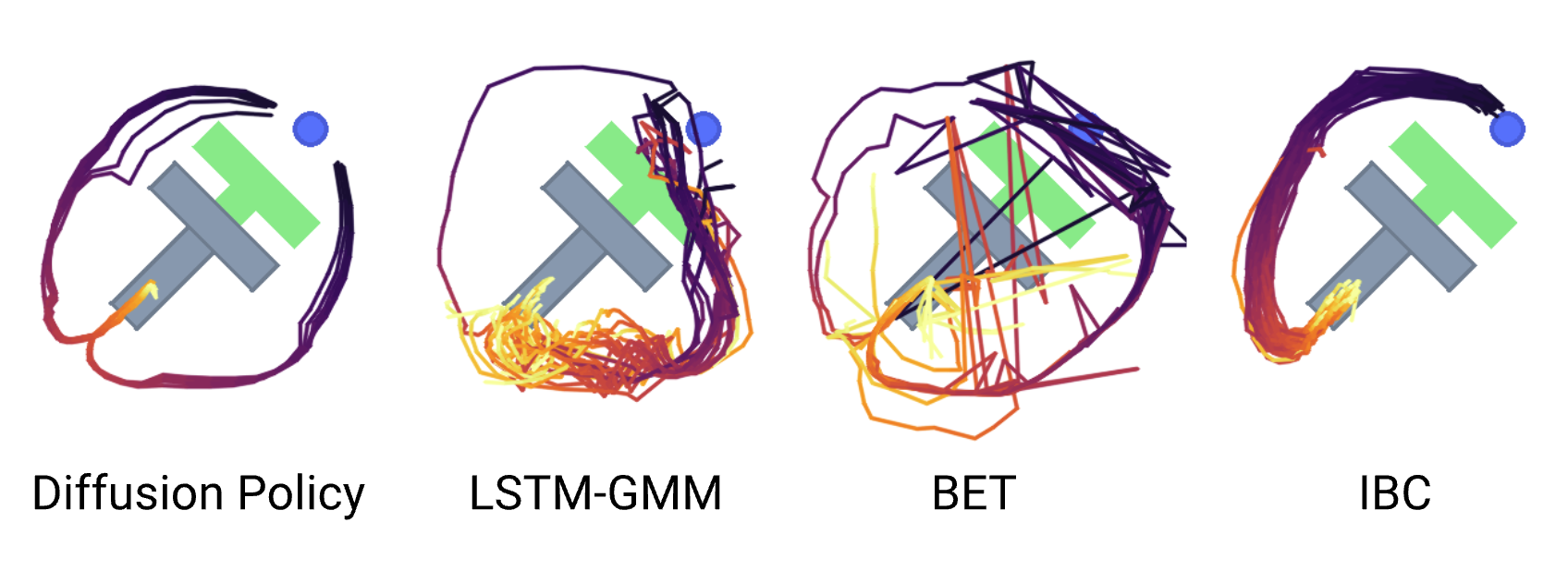
Has mention of Implicit Behavior Cloning.
Jason Ma says that these example notebooks are pretty good:
- https://colab.research.google.com/drive/1gxdkgRVfM55zihY9TFLja97cSVZOZq2B?usp=sharing#scrollTo=X-XRB_g3vsgf - State-based notebook
- https://colab.research.google.com/drive/18GIHeOQ5DyjMN8iIRZL2EKZ0745NLIpg?usp=sharing - vision-based notebook
Sample Notebook Example
They define a 1D UNet architecture ConditionalUnet1D as the noies prediction network:
Components
SinusoidalPosEmbPositional encoding for the diffusion iteration kDownsample1dStrided convolution to reduce temporal resolutionUpsample1dTransposed convolution to increase temporal resolutionConv1dBlockConv1d → GroupNorm → MishConditionalResidualBlock1DTakes two inputsxandcond.
xis passed through 2Conv1dBlockstacked together with residual connection.condis applied toxwith FiLM conditioning
Is this the same as the original UNET?
Is this
This is the sinusoidal positional embedding code (review Positional Encoding)
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return embThey use an implicit policy.