Object Detection
- Object detection works well with an online connection, but it doesn’t work deployed because you still need connection
- PointPillars doesn’t work yet (yes, because it still needs to get merged)
Object detection is the field of Computer Vision that deals with the localization (by drawing bounding boxes) and classification of objects contained in an image/video.
Some challenges:
- Objects are not fully observed, either because of occlusion or truncation (out of bounds of the camera)
- Scale (various scales of images still need to be recognized)
- Illumination changes (recognize even when it’s very bright or very dark)
Using Anchor Boxes
Object Detection occlusion should be:
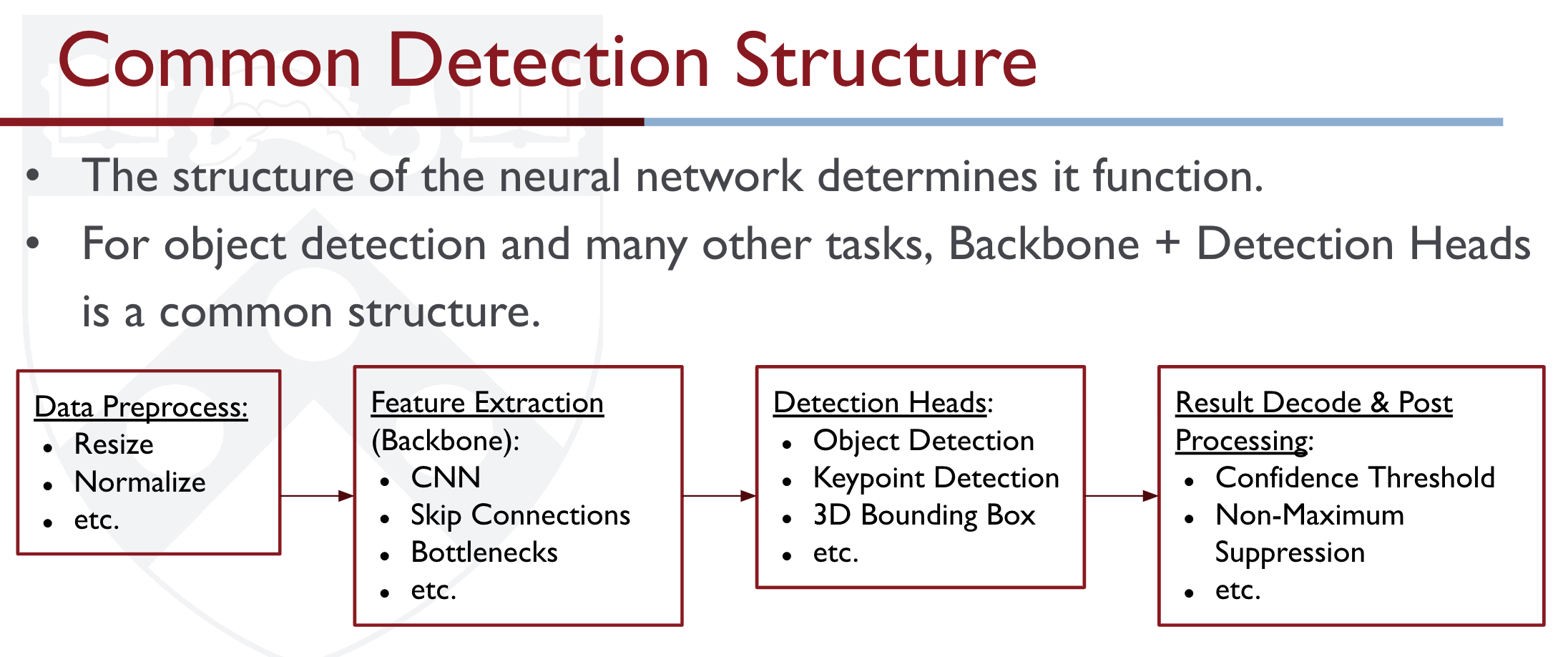
From the article
https://www.v7labs.com/blog/object-detection-guide
You don’t always want to use an Object Detection algorithm. Semantic Segmentation / Classification might be a better alternative sometime.
- Objects that are elongated—Use Instance Segmentation.
- Objects that have no physical presence—Use classification
- Objects that have no clear boundaries at different angles—Use semantic segmentation
- Objects that are often occluded—Use Instance Segmentation if possible
Two types of object detectors:
- Single-stage object detectors (end-to-end)
- Two-stage detectors
- stage 1: extract RoI (Region of interest),
- stage 2: classify and regress the RoIs
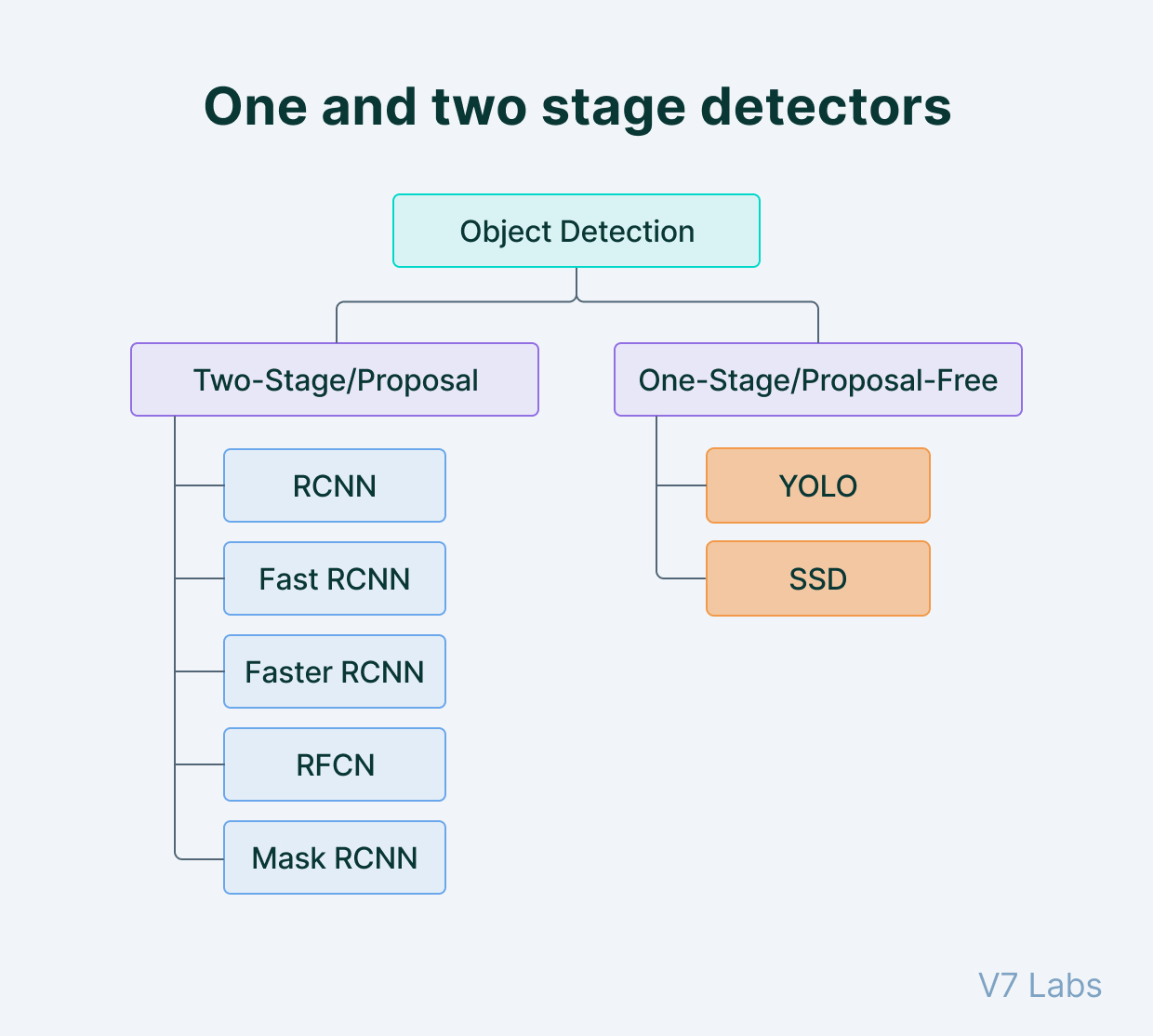
So which one is better, single stage or multistage? The paper “Focal Loss for Dense Object Detection” (you have it on Zotero) explains why one performs better than the other.
Feature extractor
Feature extractors are the most computationally expensive component of the 2D object detector. Most common extractors:
- VGG
- Resnet
- Inception
Computer Vision (Camera)
- SSD
- YOLO
- Know the differences with v2, v3, v4, etc.
- DINO → Super cool unsupervised method
- CenterNet https://github.com/xingyizhou/CenterNet
Lidar
Approaches
- Sliding Window (Exhaustive Search)
- At its core, an object detection algorithm is just an object recognition algorithm. The most straightforward approach is to generate sub-regions (patches) and apply object recognition. We thus exhaustively search for objects over the entire image ( earch different locations + different scales).
- Region Proposal (Selective Search) → R-CNN in 2013 Region proposal algorithms identify prospective objects in an image using Semantic Segmentation. Selective Search is a region proposal algorithm used in object detection. It is designed to be fast with a very high recall. It is based on computing hierarchical grouping of similar regions based on color, texture, size and shape compatibility.
Steps:
- Generate initial sub-segmentation of input image using the method describe by Felzenszwalb et al (See Semantic Segmentation)
- Recursively combine the smaller similar regions into larger ones. We use a Greedy algorithm:
- From set of regions, choose two that are most similar.
- Combine them into a single, larger region.
- Repeat the above steps for multiple iterations.
- Use the segmented region proposals to generate candidate object locations.
Afterwards, we can feed the data into a SVM classifier.
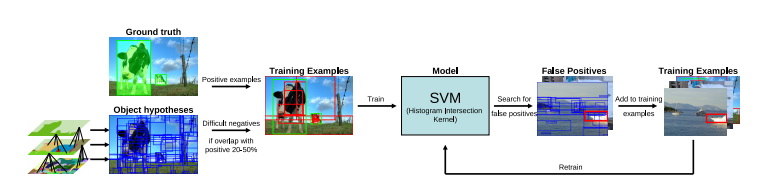
Region Proposal, Key Disadvantages:
- 3 independently trained components (not end-to-end)
- Slow!
Alternatives started to emerge: Fast(er) R-CNN, YOLO and SSD.
SSD works by using a more concise exhaustive search and adjusting bboxes over time. It eliminates bbox proposal.
Resources
Object Recognition vs. Object Detection (Harder)
Object recognition (i.e. Image Classification) identifies which objects are present in an image. It only and produces class labels with probabilities. Ex: Dog (97%).
Object Classification with Localization only works with localizing one object.
- This is done just like how we usually do Image Classification, you just add four extra parameters to train on the bounding box as well. You just have multi-task loss.
- Actually, Human Pose Estimation can be done like this. And that’s why Mediapipe only works with one pose. Because it treats it as a Object Classification with Localization problem??
On the other hand, object detection also outputs bounding boxes (x, y, width, height) to indicate the locations of the detected objects (there can be multiple objects)
Object detection comes down to drawing bounding boxes around detected objects which allow us to locate them in a given scene.
Andrew Ng Object Localization
if you only need to localize a single object with a bounding box, you can define the target y label as
Just like a Image Classification problem, we output this vector of y, where we add these 4 bbox values, almost like a linear regression problem.
- is 0 or 1, 1 meaning there is an object, probability that there is an object
- is the class i
However, for object detection, you can start with trying sliding windows detection. See above.
Building up Object Detection (CS231n 2025 Lec 9)
Single object: classification + localization
If you know there’s exactly one object, treat detection as multitask learning. CNN backbone → fc4096 splits into two heads:
- Class scores (length ) — softmax loss against ground-truth label
- Box coordinates — L2 loss against ground-truth box
Total loss is the weighted sum: . The two heads share the backbone, so localization features regularize classification and vice versa.
Multiple objects: the variable-output problem
The number of objects is unknown — could be 0, 1, or 50 — so the output dimension changes per image. Three families have emerged to handle this:
| Family | Idea | Examples |
|---|---|---|
| Region-based (two-stage) | Propose candidate regions, then classify each | R-CNN, Fast R-CNN, Faster R-CNN |
| Single-stage | Predict boxes on a fixed grid in one pass | YOLO, SSD, RetinaNet |
| Set prediction | Predict a fixed-size set of boxes, match to GT with bipartite matching | DETR |
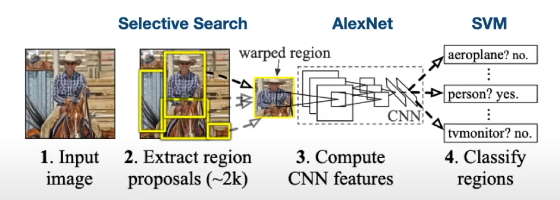
R-CNN (Girshick CVPR 2014)
- Run Selective Search (Uijlings 2013) on the image — ~2000 class-agnostic “blobby” region proposals based on color/texture/size hierarchical grouping. Fast (seconds, on CPU).
- Warp each RoI to 224×224.
- Run each through an ImageNet-pretrained ConvNet → SVMs classify + bbox regression predicts corrections to the proposal.
Problem: ~2000 independent forward passes per image. Hence “Slow R-CNN” — 49 s/image at test time.
Fast R-CNN (Girshick ICCV 2015)
Flip the order: run the whole image through the backbone once to get conv5 features, then crop the features for each RoI (project the proposal onto the feature map, then RoI-pool to a fixed size). Each per-RoI head is now a tiny network applied to a small feature crop, not a full forward pass.
Speedup: 49 s → 2.3 s/image. But now runtime is dominated by Selective Search itself (~2 s for proposals).
RoI Pool vs RoI Align
RoI Pool (Fast R-CNN): project the proposal onto the feature grid, “snap” to grid cells (rounding errors!), divide into a grid of subregions, max-pool inside each. Output is always regardless of input region size. The snap-to-grid step misaligns the features by up to half a cell — fine for detection, hurts segmentation.
RoI Align (Mask R-CNN, He 2017): no snapping. Sample features at regular floating-point points inside each subregion using bilinear interpolation:
Then max-pool the sampled values. Sub-pixel-accurate cropping, critical for mask quality. See Mask R-CNN.
Faster R-CNN (Ren NIPS 2015)
Make the CNN do the proposals too. Insert a Region Proposal Network (RPN) after the backbone:
- At each spatial position in the feature map, imagine anchor boxes of different size/aspect ratio.
- A small conv head predicts “objectness” scores (binary: object or not) and box transforms (regression from anchor to GT box).
- Sort by objectness, take top ~300 as proposals.
Trained jointly with 4 losses: RPN object/not + RPN box regression + final classification + final box regression. Two-stage detector:
- Stage 1 (once per image): backbone + RPN
- Stage 2 (once per region): RoI pool/align → classify + bbox regress
Test-time speed: 0.2 s/image. ~250× faster than R-CNN.
Single-stage: YOLO / SSD / RetinaNet
Skip the proposal stage entirely. Divide image into a grid; each cell predicts boxes with + class scores. Output tensor: . “Looks like RPN, but category-specific.” See YOLO, SSD.
Tradeoff: Faster R-CNN is slower but more accurate; SSD/YOLO much faster, less accurate (Huang et al. CVPR 2017 “Speed/accuracy trade-offs”). Bigger backbones always help.
DETR (Carion ECCV 2020): set prediction with Transformers
Pipeline: CNN backbone + positional encoding → Transformer encoder-decoder → fixed set of box predictions (e.g. , larger than max objects). Each decoder slot is an “object query” embedding.
Bipartite matching loss: at training time, find the optimal one-to-one assignment between predictions and GT boxes (Hungarian algorithm); the unmatched predictions are trained to predict “no object” . No anchors, no NMS, no region proposals — direct set prediction.
Source
CS231n 2025 Lec 9 slides 70–112, 153–174 (single object multitask, multiple objects, Selective Search, R-CNN, Fast R-CNN, RoI Pool/Align, Faster R-CNN, RPN, single-stage YOLO/SSD/RetinaNet, DETR, two-stage breakdown, R-CNN comparisons). 2026 PDF not published — using 2025 fallback (April 29, 2025).