Semantic Segmentation
Traditional technique using Graph Based Image Segmentation
https://www.mathworks.com/help/driving/ug/create-occupancy-grid-using-monocular-camera-sensor.html
Template from Kaggle:
- https://www.kaggle.com/code/ligtfeather/semantic-segmentation-is-easy-with-pytorch
- https://www.kaggle.com/code/rishabhiitbhu/unet-starter-kernel-pytorch-lb-0-88/notebook
- https://www.kaggle.com/code/xhlulu/severstal-simple-keras-u-net-boilerplate
From Article
There are 3 popular architectures:
- Fully Convolutional Network (FCN)
- U-Net (originally came from medical field)
- Mask R-CNN
In segmentation, we group adjacent regions which are similar to each other based on some criteria such as color, texture etc.
Applications
- Used for Lane Detection
- Wow, this is actually very commonly used. You can treat 2D to 3D as a semantic segmentation problem, where each classes is a particular depth, heard this idea from this Computerphile video.
- Face layers, each depth is like a different class
Image segmentation is the process of defining which pixels of an object class are found in an image.
Label each pixel in the image with a category label. We don’t differentiate instances, only care about pixels (i.e. if they are two cows, we don’t really differentiate that)
Semantic image segmentation will mark all pixels belonging to that tag, but won’t define the boundaries of each object.
Concepts
- Hough transform (see OpenCV resource)
- Canny Edge Detection (see OpenCV resource)
- Run-Length Encoding
CNN for Semantic Segmentation
We can use ConvNets to solve the image segmentation problem. Usually, there is downsampling and upsampling inside the network, kind of like an Autoencoder?
- Downsampling using Pooling for example
- Upsampling
- Bed of nails
- Max Unpooling
- Transpose Convolution (learnable upsampling, just another convolution) ??
- Other names: Deconvolution, Upconvolution, fractionally strided convolution, backward strided convolution,
Supplementary Reading: ConvNets for Semantic Segmentation
- Badrinarayanan, V., Kendall, A., & Cipolla, R. (2015). Segnet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv preprint arXiv:1511.00561.
- Zhao, H., Shi, J., Qi, X., Wang, X., & Jia, J. (2017, July). Pyramid scene parsing network. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR) (pp. 2881-2890). (State of the art)
Building up Semantic Segmentation (CS231n 2025 Lec 9)
Task definition. Label each pixel with a category from a fixed set. No notion of instances — two adjacent cows are one “cow blob”. Output shape mirrors input: class labels.
Approach 1: Sliding window (Farabet 2013, Pinheiro & Collobert 2014)
Extract a small patch around each pixel, run a CNN, predict the center pixel’s class. Correct but absurdly slow — no shared computation between overlapping patches. Mostly of historical interest.
Approach 2: Fully convolutional (Long, Shelhamer, Darrell CVPR 2015; Noh ICCV 2015)
Replace the FC head with convs, output a score volume in one forward pass, take argmax over channels per pixel. Naive version keeps full resolution throughout — too expensive at 1024×1024.
Encoder-decoder fix. Downsample with pooling/strided conv, then upsample back to input resolution. The encoder builds high-level features cheaply at low resolution; the decoder restores spatial detail.
Upsampling toolkit
| Method | What it does | Learnable? |
|---|---|---|
| Nearest Neighbor | Copy each value into a block | No |
| Bed of Nails | Place value in top-left of block, zeros elsewhere | No |
| Max Unpooling | Place value at the position remembered from a paired max-pool layer | No (but uses saved indices) |
| Transposed Convolution | Strided conv done in reverse — input element scales the kernel and writes a copy into the output | Yes |
Max Unpooling preserves edge structure better than NN/bed-of-nails because it sends each value back to its original spatial location, undoing the spatial information loss from max pool.
U-Net (Ronneberger 2015)
Symmetric encoder-decoder with copy-and-crop skip connections: each decoder stage concatenates the matching encoder feature map before its conv block. Skip connections give the decoder direct access to high-resolution features that downsampling would have erased. See U-Net.
Source
CS231n 2025 Lec 9 slides 32–69 (sliding window, FCN, in-network upsampling, Max Unpooling, Transposed Convolution, U-Net). 2026 PDF not published — using 2025 fallback (April 29, 2025, “10th Anniversary”).
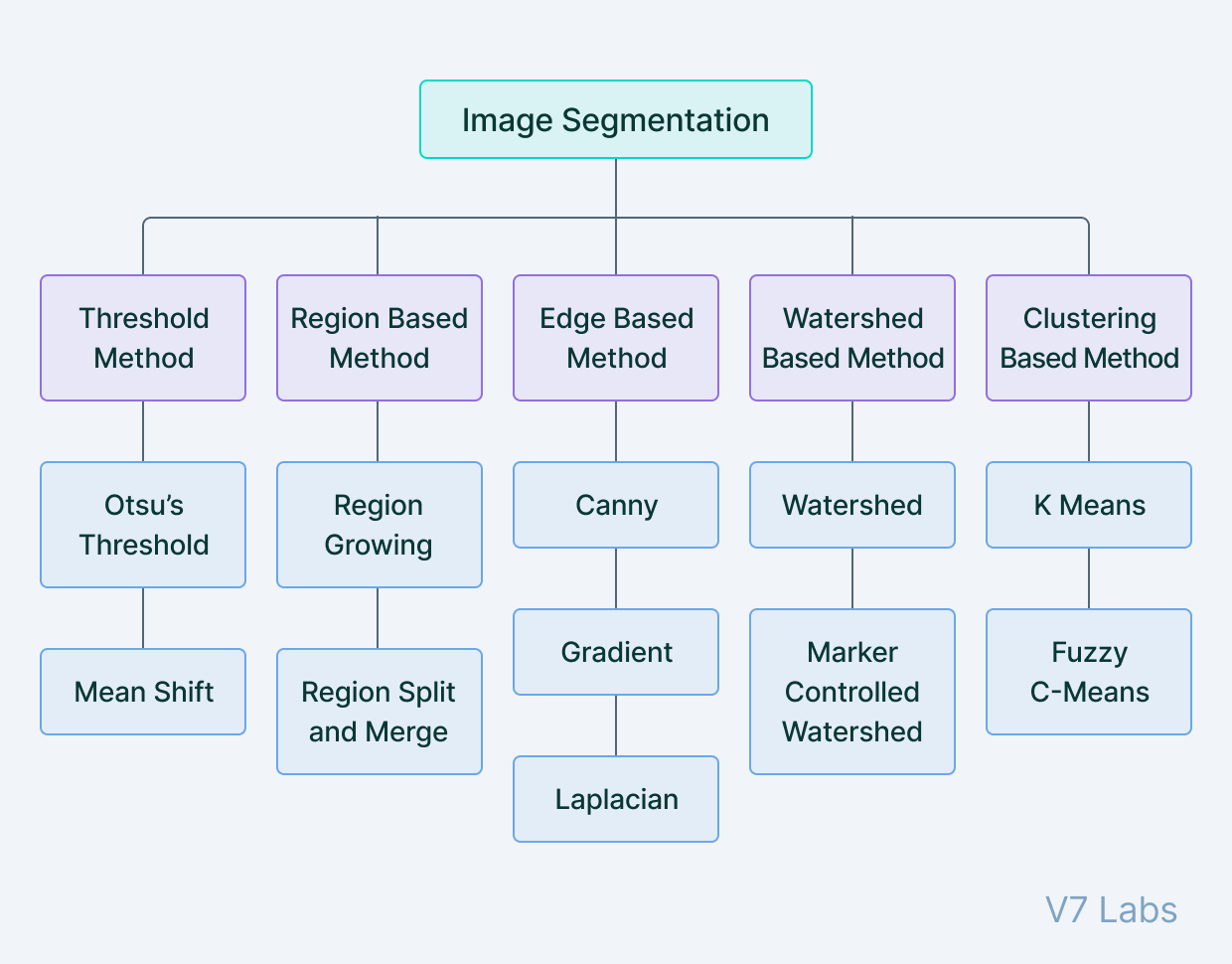
From article
https://www.v7labs.com/blog/image-segmentation-guide
Object Detection + Semantic Segmentation = Instance Segmentation (this is really cool)

- Mask R-CNN is used for Instance Segmentation (2017) ..? Idk if it is still state of the art
Image segmentation tasks can be classified into three groups based on the amount and type of information they convey:
- Semantic segmentation
- Instance segmentation
- Panoptic segmentation

The history:
Encoder decoder architectures for semantic segmentation became popular with the onset of works like SegNet (by Badrinarayanan et. a.) in 2015.