K-Means Clustering
K-Means is a simple clustering algorithm that groups similar data points into clusters by iteratively assigning points to the nearest centroid.
Common applications:
- Poker hand clustering
- Object Detection for Anchor Boxes size clustering
- Image Segmentation to downsample an image to colours
The algorithm works in three steps:
- Specify the number of clusters
- Initialize centroids by shuffling the dataset and randomly selecting data points for the centroids without replacement
- Iterate until centroids don’t change by :
- Compute sum of Squared Distance between data points and all centroids
- Allocate each data point to the cluster whose centroid is closest
- Set new centroids to the average of all data points in that cluster
Intuition
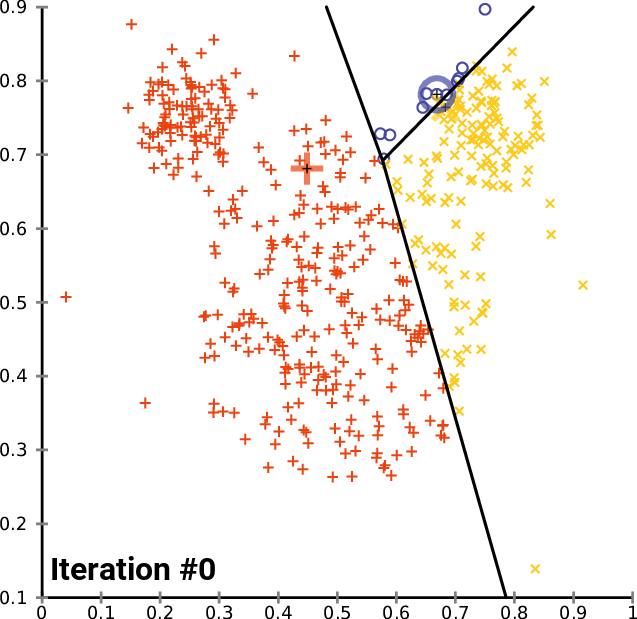
Voronoi cells, refined. Each centroid “owns” the region of space closer to it than to any other centroid. Assign each point to its owner (E-like step), then slide each centroid to the mean of the points it owns (M-like step), and the cells rearrange. Repeat. The within-cluster sum-of-squares can only go down at each step, so convergence is guaranteed, but the objective is non-convex, so the final answer depends on where you started (hence k-means++)
Bad centroids from bad initialization
Results depend heavily on initial centroid placement. In practice, run several trials of K-Means and select the one with the lowest variance. K-Means++ picks better starting centroids instead of random
Links:
- Kaggle Notebook on Visualizing High Dimensional Clusters
- Visualizing the clusters article
- Time complexity: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.KMeans.html
Distance Metrics
Why EMD vs simpler metrics like Euclidean Distance? See this Stackoverflow thread.
Tricks
Use the Triangle Inequality for speedup: https://www.researchgate.net/publication/2480121_Using_the_Triangle_Inequality_to_Accelerate_K-Means
Determining the number of Clusters
Techniques for computing the optimal number of clusters:
- Elbow method
- Average silhouette method
- Gap statistic method
Extra Resources
- https://www.cs.rice.edu/~as143/COMP642_Spring22/Scribes/Lect15
- https://towardsdatascience.com/k-means-clustering-algorithm-applications-evaluation-methods-and-drawbacks-aa03e644b48a
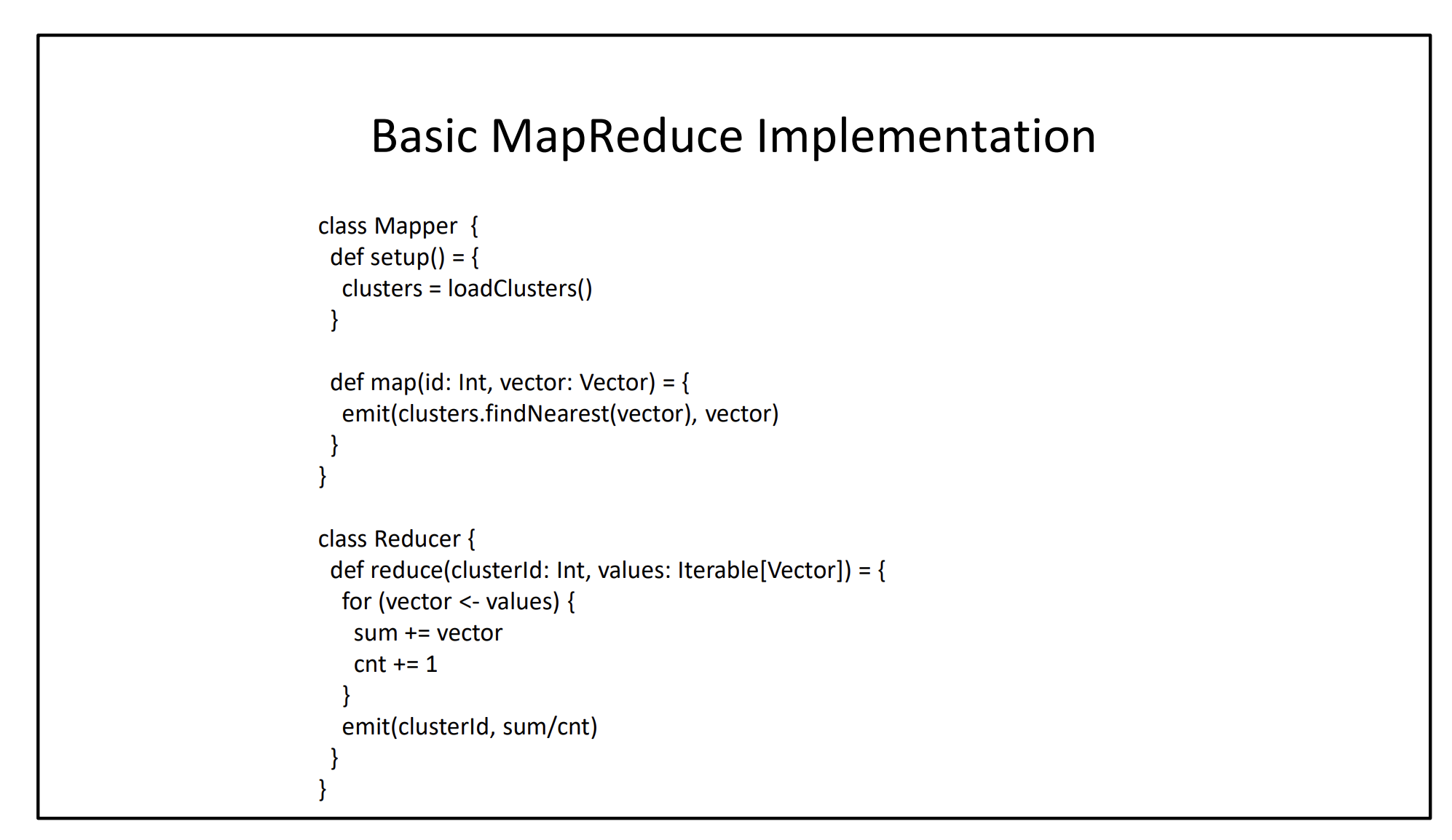
In Spark Shown in CS451