Markov Process (MDP)
Related to Markov Chain.
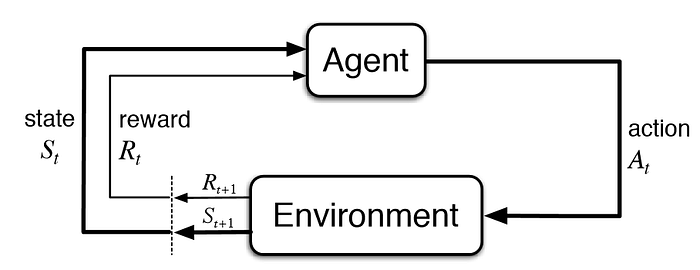
Markov decision processes formally describe an environment for reinforcement learning where the environment is fully observable
- i.e. The current state completely characterizes the process
- Almost all RL problems can be formalized as MDPs, e.g.
- Optimal control primarily deals with continuous MDPs
- Partially observable problems can be converted into MDPs
- Bandits are MDPs with one state
Markov Property
Definition
A state is Markov if and only if i.e. the state captures all relevant information from the history
-
The here is the same as that you are used to seeing in Conditional Probability
-
“The future is independent of the past given the present”
-
Once the state is known, the history may be thrown away
-
i.e. The state is a sufficient statistic of the future
State Transition Probability
“What is the probability of transitioning from state to state ?”
For a Markov state and successor state , the state transition probability is defined by
State transition matrix defines transition probabilities from all states to all successor states , where
Markov Process / Markov Chain
At a high level, a Markov process is a sequence of random states with the Markov property.
Definition
A Markov Process is a tuple
- is a finite set of states
- is a state transition probability matrix,
stands for probability.
Markov Reward Process
A Markov reward process is a Markov process with rewards (values for each state).
Definition
A Markov Reward Process is a tuple
- is a finite set of states
- is a state transition probability matrix,
- is a reward function,
- is a discount factor,
stands for probability, while stands for expected.
We can solve the MRP analytically, using the fact that we know this is a Markov Process. So we break down the value function into: Value = (immediate reward) + (discounted sum of future rewards) We know both and , and we set ourselves, so we can solve for directly. For analytical way, we can directly solve MRP, which takes around where is the number of states, and solve the matrix.
We can also use iterative algorithm with Dynamic Programming using a similar idea as the Dynamic Programming using a similar idea as the Bellman Equation.
- Initialize for all
- For until convergence (i.e. )
- ,
Markov Decision Process
Now, we add decisions. A MDP is a MRP with decisions.
Definition
A Markov Decision Process is a tuple
- is a finite set of states
- is a finite set of actions
- is a state transition probability matrix,
- is a reward function,
- is a discount factor,
The goal is to find the Optimal Policy, which maximizes the expected return.
If you have a MDP + a policy, that just becomes a MRP. So can solve using the technique above.
Also see Partially Observable Markov Decision Process
MDPs are everywhere
- Cleaning Robot
- Walking Robot
- Pole Balancing
- Tetris
- Backgammon
- Server management
- Shortest path problems
- Model for animals or people
Solving MDPs
To solve MDPs, we use Dynamic Programming in Reinforcement Learning.
Maximum Entropy MDP
Regular formulation
Maximum-entropy formulation
Continuous MDPs with Discretization
Value iteration becomes impractical when the state space is continuous.
- Solution one is to Discretization
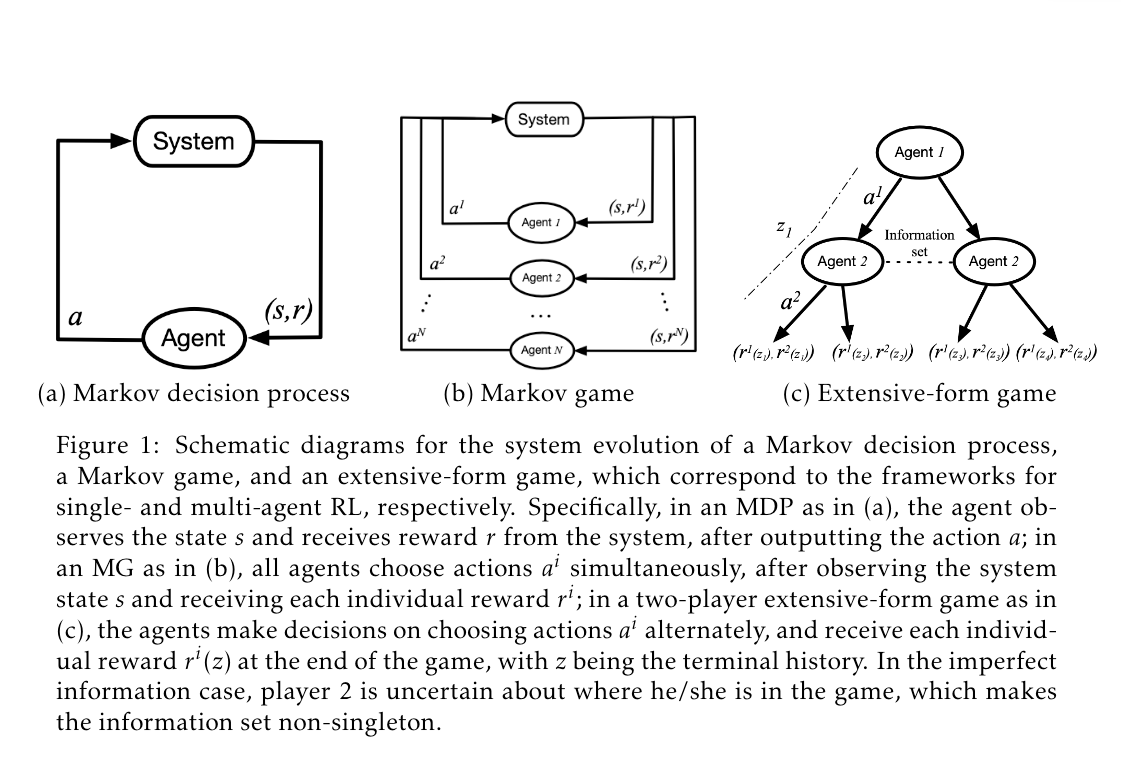
Extending MDPs
From page 7 of this paper, you have
- Markov Game
- Extensive-Form Game
Is the world markovian?
No. The Markov property makes learning and planning much, much easier.
So you can define your policy as as opposed to
- I mean this is essentially like doing proprio history