CS247: Software Engineering Principles
https://student.cs.uwaterloo.ca/~cs247/
This is one of the most fundamental course that taught me how to write C++, actually, unlike CS138.
Link to course notes here (typed out notes below).
Resources
- CS246E LaTeX notes by Sibelius
Update after the final
There were actually some questions that caught me off-guard, that I didn’t think about:
- Can you have a vector of references? Apparently not, why? See this thread
- Can you
dynamic_castaconst?- Does
reinterpret_castever fail between pointers?
Concepts
Lecture Notes
Lecture 1
We want to prevent Tampering and Forgery of our ADTs. Forgery: Creating invalid instances of an ADT Tampering: Modifying a valid instance of an ADT to became invalid in an unexpected way.
Example of Rational ADT
#include <iostream>
using namespace std;
int main() {
cout << "Enter a rational #" << endl;
Rational r,p,q; // Default constructor
// define what it means to read a rational from cin
cin >> r >> q;
// define what it means to add two rationals
p = q + r;
// define what it means to print rationals
cout << q / r << endl;
// Define copy constructor for rationals
Rational z{q};
}class Rational {
int num, denom;
public:
Rational(): num {0}, denom{1} {}
explicit Rational(int num): num {num}, denom{1} {}
Rational(int num, int denom): num {num}, denom{denom} {}
}- The
explicitkeyword is used for single parameter constructors and prevents implicit conversions, see explicit (C++)
Suppose we have the function
void f(Rational num) {
...
}If you don’t have the explicit keyword, you could do f(247). However, if you add the explicit keyword, this won’t work. You need to write
f(Rational{247});Another example:
class Node {
Node* next;
int data;
public:
Node(int data): data{data}, next{nullptr} {}
}
void q(Node n) {
...
}
q(4); // doesn't complain, because there is no explicit keyword
Another example:
void f(std::string s) {
...
}
f("Hello World"); // This doesn't complain, even though "Hello World" has type char*
- This works because
std::stringhas a single param constructor which takes in achar*and is NON-EXPLICIT.
Does the Rational ADT need to be a class? Not necessarily, ADTs are abstract, they are not tied to a particular implementation.
Could use a struct.
Classes are nicer:
- construction / destruction is guaranteed (on the stack)
- can enforce legal value ranges via access specifiers (public / private protected)
With a C-Struct, someone could easily just set denom=0. However, this is not possible with our class: denom is private, we could add logic to our constructor to reject denom=0.
- This is an example of a invariant: something about a class or ADT that you always expect to be true
We gave Rational a default constructor - a constructor that can be called with no arguments. Should all ADTs have a default constructor?
- Not necessarily - only if it makes sense. Consider a student ADT with name, id, birthday fields - no sensible defaults.
If you do not write any constructors at all, you get a compiler provided default constructor:
- Primitive fields are uninitialized (garbage values)
- Default constructs object fields
Now, we don’t need 3 different constructors for a different number of arguments. We can just use default parameters!
class Rational {
int num, denom;
public:
Rational(int num=0, int denom=1): num {num}, denom{denom} {}
}We don’t need to write different Constructor for a different number of arguments. We can just use default parameters!
// Declaration
class Rational {
int num, denom;
public:
Rational(int num=0, int denom=1): num {num}, denom{denom} {}
};
// Usage
Rational q;
Rational w{1};
Rational z{1,5};Important: Default parameters MUST be trailing.
Additionally, default parameters must only appear in the Declaration, not the Definition.
// Rational.h
class Rational {
int num, denom;
public:
Rational(int num=0, int denom=1);
};
// Rational.cc (default constructors aren't provided)
#incldue "Rational.h"
Rational::Rational(int num, int denom): num{num}, denom{denom}{}
}Using the MIL is considered better style than assigning the fields in the constructor body.
- Reference Fields
- Object Fields without Default Constructors

By Step 4: All object fields must be initialized. In not given a value via the MIL, default constructed.
Lecture 2
There are cases where using the MIL is necessary.
Constfields
class Student {
const int id;
public:
Student(int id) {
this->id = id; // does NOT compile
}
}- Reference fields
class Student {
University& myUni;
public:
Student(University& uni) {
this->myUni = uni; // does NOT compile
}
}- Object fields without default constructors
class A {
public:
A(int x) {}
}
class B {
A myA;
public:
B() {
myA = A{5}; // does NOT compile, because A does not have a default constructor
}
}- If the superclass does not have a default constructor
class A {
int x;
public:
A(int x): x{x} {}
}
class B: public A {
int y;
public:
B(int x, int y) {
this->x = x; // DOES NOT work
this->y = y;
}
}What if we gave A a default constructor?
class A {
int x;
public:
A(int x): x{x} {}
}
class B: public A {
int y;
public:
B(int x, int y) {
// DOES NOT work, because x is private, not protected.
this->x = x;
this->y = y;
}
}Correct way:
class B: public A {
int y;
public:
B(int x, int y): A{x},y{y} {}
}- This works even if A does not have a default constructor!
Now, let’s support rational operations!
To support this functionality, we need Overloading.
- Overloading is implementing two functions / methods with the same name, but differing the number or types of arguments provided
For example, the negate function overloaded
bool negate(bool b) {
return !b;
}
int negate(int x) {
return -x;
}To support cin >> r >> q, where r,q are Rationals. Define the follow operator overload:
istream& operator>>(istream& in, Rational& r) {
in >> r.num;
in >> r.denom;
return in;
}- The istream is Passed by Reference because copying is disallowed for istreams.
- The rational is also Passed by Reference because we want changes to be reflected outside this function.
- We
return into allow for chaining- In this example,
cin >> ris evaluated first cin >> r >> qsimplifies tocin >> q
- In this example,
Problem: r.num and r.denom are private fields, cannot be accessed in the operator >>
Solution 1: provide accessor methods
- provide methods
getNumandgetDenomwhich return references to the num anddenomfields - sometimes paired with mutator methods
setNum,setDenom. - i.e. getters and setters
Solution 2: Declare operator >> as a friend function
class Rational {
int num, denom;
...
friend istream& operator>>(istream& in, Rational& r);
}- the
friendgives permission for the function to access any private fields + methods of Rational
Now, support p = q+r, each variable is Rational
So we need to overload the + operator
Rational operator+(const Rational& lhs, const Rational& rhs) {
return Rational{lhs.num * rhs.denom + lhs.denom * rhs.num, lhs.denom * rhs.denom};
}
} // Would need to be a friend inside the rational classNotice that we take in args via constant reference:
- constant - don’t want lhs or rhs to change
- reference - quick no copying
Declaring all these overloads as friends is a pain.
Alternative: Define operator overloads as methods in Rational:
class Rational {
int num, denom;
public:
...
Rational operator+(const Rational& rhs) {
// Now, defined in the class, no friend is necessary
return Rational{num * rhs.denom + denom * rhs.num, denom * rhs.denom};
}
} // `this` takes the place of the lhs- Essentially,
r + qis semantically equivalent tor.operator+(q)
In python, we have r.__add__(q), see Python
Note
Operator
<<and>>are usually defined as standalone functions (outside of the class). Becausecinandcoutappears on the lhs.
What if we want r + 5? Answer: Function Overloading
class Rational {
...
Rational operator+(int rhs) {
...
}
}What about 5 + r? doesn’t work, because order of arguments matters.
unless we had the following:
Rational operator+(int lhs, const Rational& rhs) {
return rhs + lhs;
}- Note that this is a standalone function, defined outside of the class.
What about p = q + r?
Compiler provides a Copy Assignment Operator for you. We can also write our own.
class Rational {
...
public:
Rational& operator=(const Rational& rhs) {
num = rhs.num;
denom = rhs.denom;
return *this;
}
}We can chain the = operator:
a = b = c = d = e; // Evaluates right to left, returns the value that was set -> d=e executes first. Returns ref to do
// simplifies to a = b = c = d;
// simplifies to a = b = c;
// simplifies to a = b;
// simplifies to a;Lecture 3
There are some operator overloads that MUST be defined as methods. These are:
operator=operator[]operator->operator()operator TwhereTis a type
Supporting division of Rationals, e.g. q/r.
Exercise: Supporting cout << q << endl where q is a Rational.
Do the following:
class Rational {
...
friend ostream& operator<<(ostream& out, const Rational& r);
}
ostream& operator<<(ostream& out, const Rational& r) {
out << r.num << "/" << r.denom;
return out; // For chaining
}Usually, we don’t provide endl in the operator << definition, because we don’t want to force our users to use new lines.
Consider:
ofstream file {"file.txt"};
Rational r {5, 7};
file << r << endl;Our operator << and operator >> definitions also work for reading from and printing to files (and other types of streams).
Finally, Rational z{q}; or Rational z = q; or Rational z(q);
- Running the Copy Constructor
- Compiler provides a Copy Constructor that simply copies all the fields. We can also write our own.
class Rational {
...
public:
Rational(const Rational& other): num{other.num}, denom {other.denom} {}
};
Rational q{3,4};
Rational z{q}; // Copy ctor
Rational r{2,3};
Rational r{1,2};
r = q; // Copy Assignment operatorHaving written all these operator overloads, Rational ADT is easy to use from a client perspective.
Takeaways
- Overloading operators gives us a common syntax
- Classes allow us to enforce invariants, good ADT design
- Friends can be used (sparingly) to give access to private fields
Value Categories Every expression in C++ has both a type and a Value Category.
We will discuss 2 categories: lvalues and rvalues
lvalue
An lvalue is any expression that you can take the address of.
For example:
int x = 5;
f(x); - In the above, this expression
x- we can take its address, therefore it is an lvalue.
rvalue
An rvalue is a temporary value, it will be destroyed “soon”.
f(5)5is an rvalue, as we cannot take the address of5.
Another example
string f() {
return "Hello World";
}
string s = f();- this expression
f()is an rvalue. The returned result offonly exists until the end of the line
We cannot run &f() - the string isn’t stored anywhere permanently, just a temporary until it is saved into s
The references we have seen so far are lvalue references. These can only bind to expressions that are lvalues.
For example:
int x = 5;
int& y = x; // ✓ this is goodHowever,
int& y = 5; // ✕ this doesn't compile. 5 is an rvalue.An exception: We can bind rvalues to const lvalue references.
f(int& x) {
...
}
f(5) // ✕ prohibited
g(const int& x) {
...
}
g(5); // ✓ this is allowed, we won't modify x, the compiler creates a temporary memory location to store the 5 in.We can also create rvalue references. Extend the lifetime of the rvalue to the lifetime of the reference.
String f() {
return "Hello World";
}
String&& s = f(); // String&& is an rvalue reference- We can use the temporary value returned by
ffor as long assexists.
Most commonly used for overloading functions based on the value category of the expression.
void f(const string& s) {
cout << "1" << endl;
}
void f(string&& s) {
cout << "2" << endl;
}
string s{"cs247"};
f(s); // "1"
f(string{"CS247"}); // "2"Why is this useful? We’ll see shortly.
Finally, note that type and value categories are independent properties.
void f(string&& s) {
cout << s << endl;
}- Here, although
sreferences an rvalue, we can take s’s addresssis an lvalue.
Linked List ADT
A slightly more complicated ADT example.
Specifically, I want to leverage lvalue / rvalue knowledge proficiency. We’ll focus on invariants + encapsulation later. For now, we’ll focus on correctness and efficiency.
struct Node {
string data;
Node* next;
}I want the following client node:
Node n {"a", new Node{"b", new Node{"c", nullptr}}};
Node p{n};
p.next->data = "z";
cout << p; // a, z, c
cout << n; // a b cFirst, constructor:
Node::Node(const string& data, Node* next): data{data}, next{next} {}Next: Node p{n} this executes the copy constructor - provided by compiler. Copies each field.
Now, p.next->data = "z" modifies n as well. We have shared data. We’ll define our own copy constructor that recursively copies the data structure.
Node::Node(const Node& other): data{other.data}, next {other.next ? new Node{*(other.next)} : nullptr} {}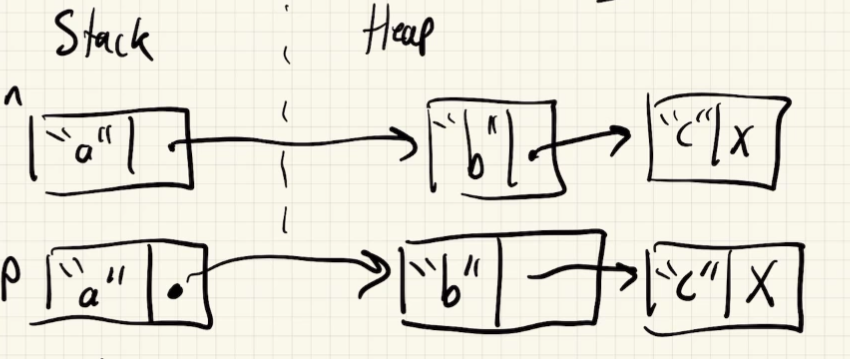
- This is a deep copy, as opposed to a shallow copy.
Lecture 4
This time: Linked List ADT continued.
Move Constructor + Move Assignment Operator. Elision. Encapsulation.
Node n {"a", new Node {"b", new Node{"c", nullptr}}};
Issue: Although n is freed, the rest of the Nodes in the list are on the heap, must also be freed.
We will write a destructor, which runs when stack allocated objects go out of scope, and when heap allocated objects are freed.
Node::~Node() { delete next; };Complaint: Efficiency.
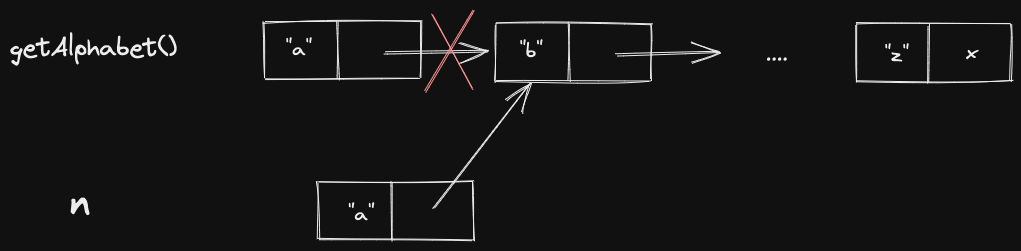
Node getAlphabet() {
return Node{"a", new Node{"b", ... new Node{"z", nullptr}...}};
}
Node n{getAlphabet()};In memory, looks like the following:

- Here, we’ve copied 26 nodes, then delete the originals immediately
We can observe that getAlphabet() is a rvalue. It’s going to be deleted by the next line. No one else will use that memory. We can steal it.
We’ll write a Move Constructor for rvalues, which will be faster.
Node::Node(Node&& other): data{other.data}, next {other.next} {
other.next = nullptr;
}
One more slight optimization:
data {other.data}other.datahas an address, its an lvalue. This invokes the copy constructor for the data string. Even thoughother.datawill die soon. We’d prefer to run the string move constructor.
data {std::move(other.data)}std::moveis included in<utility>, forces an lvalue to be treated like an rvalue. Move Constructor runs.
We still have data sharing:
Node n{"a", new Node{"b", new Node{"c", nullptr}}};
Node p{"d", new Node{"e", nullptr}};
p = n; // runs the copy assignment operatorCompiler provided assignment operator does shallow copies of pointers. Data sharing again, leaked node.
We’ll implement our own copy assignment operator.
Attempt 1:
Node& Node::operator=(const Node& other) {
delete next;
data = other.data;
next = other.next ? new Node{*(other.next)} : nullptr;
return *this;
}Example of when the above doesn’t work:
Node n {"a", new Node{"b", new Node{"c", nullptr}}};
n = n;To protect against self-assignment, add the following to the beginning of the assignment operator.
if (this == &other) return *this;We’ll rearrange th copy assignment operator slightly. new has the possibility to reject our request for more memory. We’ll then quit the function.
Call new first so if it fails, we haven’t deleted anything yet.
Working copy assignment operator:
Node& Node::operator=(const Node& other) {
if (this == &other) return *this;
Node* temp = other.next ? new Node{*(other.next)} : nullptr;
data = other.data;
delete next;
next = temp;
return *this;
}There is some code duplication between copy constructor and copy assignment operator. Can address this using the Copy-and-Swap Idiom:
Node& Node::operator=(const Node& other) {
Node tmp{other};
std::swap(data, tmp.data);
std::swap(next, tmp.next);
return *this;
}Exercise: check what happens with self-assignment.
Finally: Move Assignment Operator for more efficiency.
Node& Node::operator=(Node&& other) {
std::swap(data, other.data);
std::swap(next, other.next);
return *this;
}Exercise: write this without swapping.
If you don’t define a move constructor / assignment operator but you do define a copy constructor / assignment op, compiler will use copies in all scenarios.
Rule of Five: If you write one of the following, you should usually write all: Destructor, Copy Constructor, Copy Assignment Operator, Move Constructor, Move Assignment Operator.
Elision
Rational makeRational() {return Rational{1, 5}};
Rational r = makeRational(); // what runs here?In g++, std=c++14, neither move nor copy gets called. This is called Elision.
In certain cases, compiler can skip calling copy / more constructers, instead writing the object’s value s directly into its final location.
Another example
void doMath(Rational r) {
...
}
doMath(makeRational());Here, {1,5} is directly written into r.
Note: Elision is possible, even if it changes program output.
- Not expected to know all possible cases, just that it’s possible.
Disable with the flag -fno-elide-constructors (slows down program though)
Lecture 5
Forgery:
Node n {"bad ptr", (Node *) 0x2117};0x2117is a completely random memory address- Most likely, a segmentation fault on any kind of use.
Tampering:
Node n {"a", nullptr};
n.next = &n; // A cycle of 1 node
Node n {"abc", nullptr};
Node p {"def", &n}; // Try to delete stack memory when the destructor runsAll these issues are from a common problem: Representation Exposure.
Every ADT has a representation in memory somehow. For example, linked lists are implemented via a series of nodes
If the client gains access to the memory, we call that Representation Exposure. Client can use this knowledge to do things we don’t expect.
We have expectations / rules for all linked lists:
- All nodes are heap allocated (or next is nullptr)
- No sharing between separated lists
- No cycles in our list
Clients should not need to uphold these invariants, its our responsibility.
Solution: Encapsulation. We provide public methods for the client to interact with our List.
// list.h
class List {
struct Node; // forward declaration of a private, nested, class.
Node* head = nullptr; // front of our list
public:
List(); // creates empty list;
~List();
void push(const string& s);
string& ith(int i);
}// list.cc
struct List::Node {
// same as before
...
}
List::List() {}
List::~List() { delete head; }
void List::push(const string& s) {
head = new Node {s, head};
}
string& List::ith(int i) {
Node* cur = head;
for (int x=0;x<i;++x) {
cur = cur->next;
return cur->data;
}
}This solves our representation exposure problem. Client has no knowledge of Nodes, no access to internal memory representation, no tampering / forgery allowed.
Lists are slow! th is a not a constant time operation. Takes steps to find the -th node in the list.
for (i=0;i<100000;i++) cout << l.ith(i);Total time is , so
We can’t just give clients access to Nodes again, because we would get Representation Exposure.
Design Patterns: Effective solutions to common problems
Problem: Efficient looping over a data structure while maintaining encapsulation.
Pattern: Iterator Design Pattern: provide an abstraction for pointers.
Example:
int a[s] = {247, 1, -100, 5, 60};
for (int *p = a;p!=(a+s);++p) {
cout < *p << endl;
}Our client’s use of an iterator will look like:
List l;
for (List::Iterator it=l.begin();it != l.end();++it){
cout << *it << endl;
}These are the functions we need to implement:
- for
List:beginandendfunctions that return iterators - for
List::Iterator:!=to compare++to go to the next node*to get the string at current Node.
Implementation
Class List {
...
public:
class Iterator {
Node* cur;
public:
Iterator(Node* cur): cur{cur} {}
bool operator!=(const Iterator& o) {
return cur != o.cur;
}
string& operator*() {
return cur->data;
}
Iterator& operator++() {
cur = cur->next;
return *this;
}
} // end of iterator
Iterator begin() {return Iterator{head}};
Iterator end() {return Iterator{nullptr}};
}post-fix vs prefix ++
The teacher uses specifically prefix ++ so that the function overloaded is
Iterator& operator++(). If we wanted it for post-fix ++, we would doIterator& operator++(int i)(yes disgusting)
If you implement an iterator like this, we can use the range-based for loop syntax:
for (string s: l) cout << s << endl;- When there is no reference (no
&sign), it creates a copy fromcur->dataintos; - Under the hood, it calls
l.begin()andl.end()to iterate through
for (string s: l) {
s = "";
} // no effect on the list
for (string& s: l) {
s = "";
} // sets strings in the list to emptycan also use auto for type deduction:
for (auto s: l) { // determines s is a string for us
...
}Note: auto drops references, so if you want to modify l, use auto&.
Iterator is a public nested class, with a public constructor.
Worry of Forgery: auto it = List::Iterator {nullptr};
This could be a problem for other kinds of Iterators where nullptr is not used.
Solution: Give iterator a private constructor.
class List {
...
class Iterator {
Node* cur;
Iterator(Node* cur): cur{cur} {}
public:
// as before
friend List; // Lists can be use private methods of Iterators, namely the constructor
}
}Warning
In general: be cautious when using friends, weakens Encapsulation. Only make friend (C++)s if they can do something for you!
Subtle issue:
void useList(const List& l) {
...
for (string s: l) { ... } // this calls l.begin(), l.end();
...
}Doesn’t compile! How should we know that begin/end won’t modify the fields of this constant l?
Solution: Declare begin/end as const methods, promise we won’t modify fields.
Iterator begin() const {return Iterator{head}};
Iterator end() const {return Iterator{nullptr}};- a constant object (or const ref to an object) may only have
constmethods called on it. - Now, it compiles! But it is actually BAD
We can still modify a const List& by using its iterator.
INSERT EXAMPLE HEREIn next lecture, we’ll talk about physical constness vs. logical constness.
Lecture 6
We saw that we could modify a const List& by using its iterator.
This is due to the difference between physical and logical constness.
- Physical constness is about a particular object’s implementation. Compiler guarantees this for const objects/const refs. Ensures the fields won’t change.
- Logical constness asks not only for the fields to be immutable, but also that the memory associated with the representation of the ADT doesn’t change.
How to achieve logical constness?
beginandendcannot be cast methods, they return Iterators that return modifiable string refs viaoperator*
We’ll write additional methods cbegin/cend which return const Iterators, which will only provide a cast string& when calling operator*.
class List {
...
public:
class ConstIterator {
Node* cur;
ConstIterator(Node* cur): cur{cur} {}
public:
const string& operator*(){return cur->data};
bool operator!=(const Const Iterator& o) {...};
ConstIterator& operator++() {...};
};
Iterator begin() {return Iterator{head};};
ConstIterator cbegin() const {return ConstIterator{head};};
Iterator end() {return Iterator{nullptr};};
ConstIterator end() const {return ConstIterator{nullptr};};
}Now, we cannot call begin / end on a const List&. Can only call cbegin / cend, these don’t allow us to modify the list.
Complaint: duplication between two iterators. Fix this using a C++ Template.
Template classes are allowed to be parametrized via the type provided.
Classic example: C++ Standard Template Library.
vector<int>vs.vector<string>is implemented using Template (C++).
Specify the return type of operator* as a template parameter, rest of the code is the same.
class List {
...
public:
template<typename T> class MyIterator {
Node* cur;
MyIterator<T>(Node* cur): cur{cur} {}
public:
T operator*() {return cur->data;};
bool operator!=(const MyIterator<T>& other) {...};
MyIterator<T>& operator++() {...};
friend List;
};
using Iterator=MyIterator<string&>;
using ConstIterator=MyIteartor<const string&>;
Iterator begin() {return Iterator{head};};
ConstIterator cbegin() const {return ConstIterator{head};};
Iterator end() {return Iterator{nullptr};};
ConstIterator cend() const {return ConstIterator{nullptr};};
}Note: Template definition of methods must be written in the header file, because the template needs to know the next field exists.
how do template work? (briefly)
For each use of
MyIterator<T>, compiler generates another copy of the class withTsubstituted where necessary. Afterwards, compiles as usual.No runtime cost using templates, it is as if we wrote our own
Iterator/ConstIterator.
Separate Compilations
In List.h (original version), we provided a forward declaration of struct Node. Provide definition of the class in the .cc file.
This is especially useful for separate compilation.
g++ -std=c+=14 List.cc -c-ccompiler flag lets us produce an object file (usually ends with.o)
Think of object files as containing the machine instructions for that code (ahhh we saw this in CS241E with Linking).
Use object files to store the result of compilation, and reuse it if the .cc files haven’t changed. With many files, significant speedup while developing. We prefer to put implementations in .cc file for the following reasons:
List.ccchanges recompileList.ccintoList.o, Link object files together to get an executable.List.hchanges all.ccfiles that includeList.hmust recompileA.hincludesList.hany.ccfiles includingA.hmust change
Relink all .o files together.
We prefer forward declarations of classes where possible - minimizes recompilation.
When can we simply forward declare, and when do we need to use
#include?See the example below.
class A {...}; // A.h
class B: public A { // B.h
...
}
class C { // C.h
A myA;
}
class D {
A* aP;
}
class E {
A f(A x);
}
class F {
A f(A x) {
x.doMethod();
...
}
}BandCrequire#includein order to determine their size and compile them.Dall pointers are the same size, just use a forward declarationEwe don’t need to know the size ofA, just thatAexists for type-checking purposesFmust#includeto know thatdoMethodexists
Lecture 7
This files we gave in A1 looked like:
#ifndef MOTION2D_H
#define MOTION2D_H
...
#endif - The above are Preprocessor directives - commands that allow transformations of the source code before it is compiled.
#include "file" - replaces this line with the contents of file.
Consider an example: Linear Algebra modules.
// Vec.h
struct Vec {
int x,y;
};// Matrix.h
#include "Vec.h"
struct Matrix {
Vec e1;
Vec e2;
};// main.cc
#include "vec.h"
#include "Matrix.h"
int main() {
Vec v1{1,2};
vec v2{3,4};
Matrix m{v1, v2};
}
main.cc includes vec.h
main.cc includes matrix.h, includes vec.h
- two definition of
struct vecinmain.cc, not allowed
To fix this issue of multiple definitions, use “include guards”:
#ifndef
#define
...
#endif#ifndef VARIABLE: The code between#ifndefand#endifwill only be seen by the compiler ifVARIABLEis not defined.#define VARIABLEdefines a preprocessor variable.- Include Guard
#ifndef FILE_H
#define FILE_H
...
#endifWorks because once File.h is included once, the variable becomes defined, so in all future includes the block is omitted.
This doesn't fix all issues
There is an issue with circular dependencies. Consider the following example:
class A {
B* myB;
}
class B {
A* myA;
}The issue is that each class needs to know the other exists before it can be created.
Solution: Break circular dependencies chain using forward declarations.
Separate compilation
Speeds up compilation and development time: change one .cc file → update the .o file, relink with other old .o files.
Issue: Change a .h file, then many .cc files might need to be recompiled. Mental energy to figure out the dependencies and just recompile the relevant .cc files. Might be faster to just recompile everything.
Solution: Use a build automation system. Keep track of what files have changed, keep track of dependencies in compilation, just recompiles the minimal # of files to make a new executable.
We’ll discuss make: Create a Makefile
Example: main.cc (includes List.h), List.h, List.cc (includes List.h)
Makefile (v1)
myprogram: main.o, List.o
myprogram (TAB) g++ main.o List.o -o myprogram- General format for first line is
target: dependencies g++ main.o List.o -o myprogramis called the recipe
main.o : main.cc List.h
g++ -std=c++14 main.cc -cList.o : List.cc List.h
g++ -std=c++14 main.cc -cThis text is in a Makefile in our directory.
make → creates the first target
Looks at the last modified time of dependencies.
If last modified time is newer for a dependency than a target => target is out of date, recreate it.
Still too much work! Still requires lots of updates to our makefile.
Makefile (V2)
CXX = g++
CXXFLAGS = -std=c++14 -Wall -g -MMD
EXEC = myprogram
CCFILES = $(wildcard *.cc)
OBJECTS = ${CCFILES:.cc=.o}
DEPENDS = ${CCFILES:.cc=.d}
${EXEC}: ${OBJECTS}
${CXX} ${CXXFLAGS} ${OBJECTS} -o ${EXEC}
-include ${DEPENDS}
For CXXFLAGS
-Wallfor more warnings-gfor extra debugging support-MMDto include${DEPENDS}include ${DEPENDS}compiles all object files with dependencies usingCXXandCXXFLAGS
Software Development lifecycle:
- clients specs program build test/debug it
Program uses source control and is released.
Lecture 8
Agile Method Client specs planning programming building testing/debugging source control releasing client (goes in a loop)
- Client is looped into the process.
- Typically, work is done in 1-2 week “sprints”
- Basically, no one uses Waterfall Method
Next: Testing / Debugging Debugging in C++: Valgrind and gdb
Valgrind
Valgrind’s primary use is as a memory checking tool. It provides a virtual CPU that it executes your program on - checks for memory access, etc.
Typically programs executed through valgrind are 3-4x slower than usual (don’t use it for performance monitoring).
Important
It’s important when using valgrind or gdb to compile with the
-gflag.
Other important information:
- Using
--leak-check=fullallows you to see where leaked memory was allocated - Valgrind can only inform on memory leaks for one particular invocation of the program
- Highlights the importance of designing various test cases that hit each part of the program.
Can also detect invalid reads: report the line of your source code where the invalid read happened.
Invalid write - we get 3 pieces of info:
- where the invalid write occurred
- where the memory was freed
- where the memory was initially allocated
Can also detect invalid uses of delete / delete[].
GDB
gdb = GNU Debugger: Useful for inspecting variables, seeing control flow of program.
gdb ./myProgram
run - runs the program
runa arg1 arg2 arg3
run < test8.in
break file: line-number
break fn-name
- set a breakpoint, allows us to stop program at this point
next - runs one line of the program
layout src - nicer display for source code
print variable - allows you to see value of that variable at that time
refresh - fix the layout src display
step - runs one instruction of the program
list - show surrounding lines of the pgoram
backtrace - lists the sequence of function calls that got you to your current location
up/down - change the function in the call stack we are observing so as to inspect other variables
set var - allows us to set a variable at runtime
continue - runs the program until the next breakpoint
display var - prints the value of var after each next/step
undipslay 1 - stops displaying first var set with display
watch var - breaks the program whenever var is changed
delete breakpoint number - rename break point from use (watch and break)
Lecture 9
- Source control: manage source code for your program (version1, version2)
- Wants: collaborate with others, have a version history
- historically people used SUN, subversion, mercurial
- Most people nowadays just use Git
- Create a git repository:
git initfrom within a directory - git has a staging area, prepare what files which parts will be committed
- commit unit of work - understanding of how ideas/data structures developed over time, commit early and often to see
- a commit = a unit of work - you should commit early and commit often
Basic Commands
git add- allows you to add changed files to staging areagit status- lets us see which branch we’re on, which files / changes will be committed, etc.git add -plets you stage interactivelygit diffto see the difference between all (unstaged AND staged) files and the most recent commitgit diff --stagedto see the difference between staged files and the most recent commit
One thing we may want to do is develop features or work on refactors separately form other development.
git branch branchNamegit checkout branchNameto swatch between branches
Example: Let’s say we’re on master branch.
git branch feature
git checkout feature
git commit
git checkout master
git commitgit merge branchNamecreates a new commit with parents that are the latest commits on the current branch and branchName.git merge featuregit log- shows a history of commitsgit push- send work to a remote branchgit pull- pulls work from remote branch, merges as well.
System Modeling
Goal: visualize classes and the relationships between them at a high level
Popular standard: UML

Modeling class relationships
Composition, “owns-a” relationship
If A owns-a B, then generally:
- B does not have an independent existence for A
- If A dies, then B dies
- If A is copied, B is copied as well (deep copy)
Typically, this is implemented in C++ via object fields.
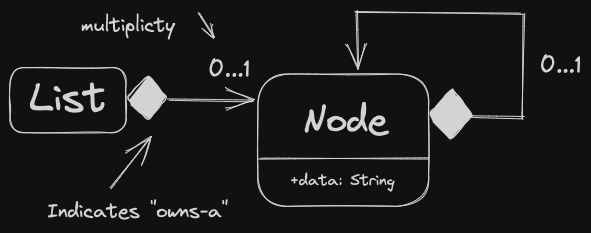
Aggregation, “has-a” relationship If A has-a B, then generally:
Bhas an independent existence outside ofA- If
Adies,Blives on - If
Ais copied,Bisn’t (shallow copy)
Generally implemented via references or non-owning pointers (one you don’t delete).
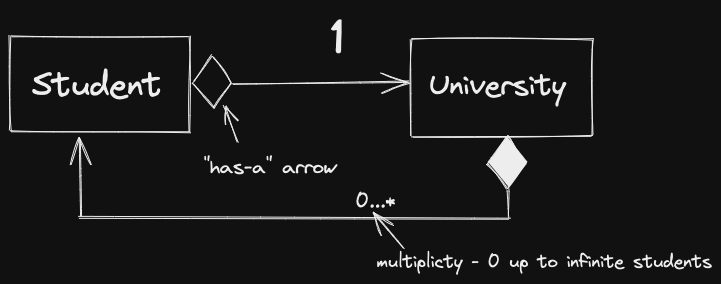
If a student dies, university lives on. if we copy a student, don’t copy whole university.
Specialization: “is-a” relationship.
- One class is a “version” of another class
- Typically subclassing or subtyping relationship
- If B is-a A, then we should be able to substitute something of type B, wherever we expect something of type A.
In C++, achieve this via public Inheritance.
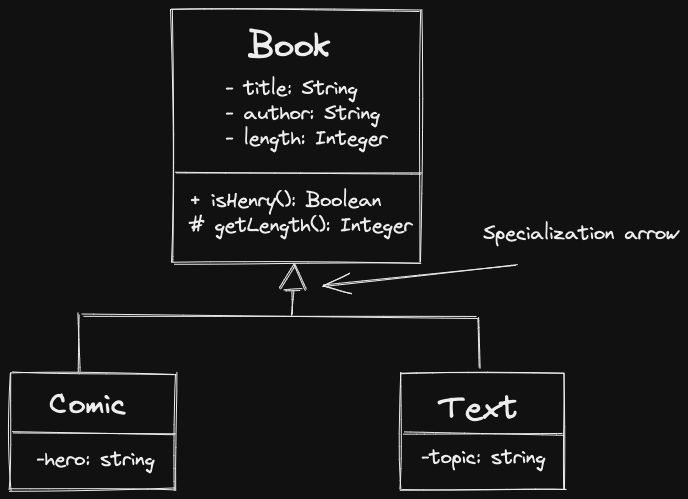
class Book {
string title, author;
int length;
protected:
int getLength() const {
return length;
}
public:
Book(string title, string author, int length): title{title}, author{author}, length{length} {}
}
virtual bool isHeavy() const {
return length > 200;
}
}class Text: public Book {
string topic;
public:
Text(string title, string author, int legnth, string topic): Book{title, author, length}, topic {topic} {}
bool isHeavy() const override {
return getLength() > 500;
}
}Why Book{title, author, length}?
Recall the 4 steps of object construction (from Constructor)
- Space is allocated
- Call the superclass constructor
- Initialize fields via a member initialization list (MIL)
- Run the constructor body
We cannot set title, author, length because they are private to book. It will use Books default constructor, won’t compile if default constructor does not exist.
Let’s discuss Virtual Method and Overriding.
Virtual keyword is used for achieving dynamic dispatch for polymorphic types.
Dynamic Dispatch: choosing which function to run at run-time as opposed to compile time.
Consider the following
Book* b;
string choice;
cin >> choice;
if (choice == "Book") {
b = new Book{...};
} else {
b = new Text{...};
}
cout << b->isHeavy() << endl;b has two types associated with it. See Static vs. Dynamic Type of Pointer
- static type:
bis aBook*, compiler knows this. - Dynamic type: describes what type
bis pointing to at run-time. May depend on user-input, cannot be determined by the compiler
Lecture 10
How do we know which method call in the hierarchy is invoked for b.isHeavy() or b->isHeavy()? Notes copied into Virtual Method.
- Is the method being called on an object? If so, always use the static type to determine which method is called.
Book b{...}; // b.isHeavy -> calls Book::isHeavy
Text t{...}; // t.isHeavy -> calls Text:::isHeavy
Book b = Text{...};
b.isHeavy(); // b.isHeavy -> calls Book::isHeavy- Is the method called via pointer or reference? a) Is the method NOT declared as virtual? - Use the static type to determine which method to call.
Book* b = new Text{...}
b->nonVirtual(); // Calls book::nonVirtualb) Is the method virtual? Use the dynamic type to determine which method is called.
Book *b = new Text{...};
b->isHeavy(); calls text::isHeavyWe can support
vector<Book*> bookcase;
bookcase.push_back(new Book{...});
bookcase.push_back(new Text{...});
bookcase.push_back(new Comic{...});
for (auto book: bookcase) {
cout << book->isHeavy() << endl;
}Each iteration calls a different isHeavy method.
What about
(*book).isHeavy()?
(*book).isHeavy()calls the correct method as well, because*bookyields aBook&, i.e. a reference.
What is the purpose of the override keyword?
- It has no effect on the executable that is created.
However, can be helpful for catching bugs.
class Text {
...
bool isHeavy(); // missing a const! won't override Book's virtual isHeavy because the signatures do not match.
}Specifying override will have have the compiler warn you if the signature does not match a superclass’ virtual method.
Why not just declare everything as virtual for simplicity?
Consider the example below.
struct Vec {
int x,y;
void doSomething();
}
struct Vec2 {
int x,y;
virtual void doSomething();
}
Vec v{1,2};
Vec2 w{3,4};
cout << sizeof(v); // 8
cout << sizeof(w); // 16- Declaring
doSomethingas virtual doubles the size of our vec object, program consumes more RAM, slower in general. - This extra 8 bytes is storing the vptr - virtual pointer. vptr allows us to achieve dynamic dispatch with virtual functions.
Remember, in MIPS, function calls use the JALR instruction. Saves a register, jumps PC to a specific function’s memory address, hardcoded in that machine instruction.
With dynamic dispatch, which function to jump to could depend on user input. Cannot be hardcoded.
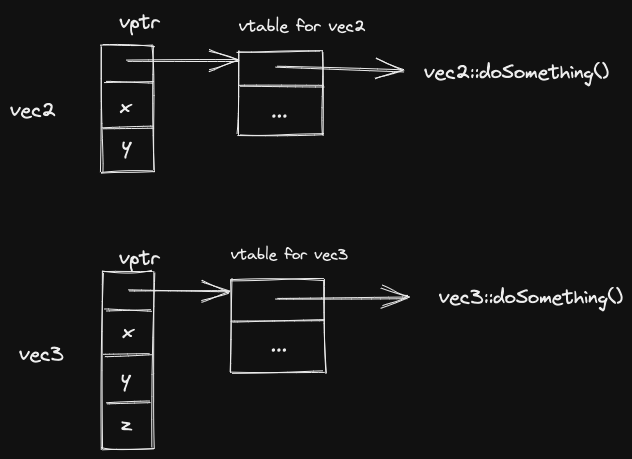
struct Vec2 {
int x,y;
virtual void doSomething();
}
struct Vec3: public Vec2 {
int z;
void doSomething() override;
}
string choice;
cin >> choice;
vec2* v;
if (choice == "Vec2") v = new Vec2{...};
else v = new Vec3{...};
v->doSomething();how the virtual function is actually decided
When we create a vec2 or vec3, we know what type of object we’re creating, so we can fill in the appropriate vptr for that object.
Now, in either case, we can simply follow the vptr, get to the vtable, and find the function address for the doSomething method.
Extra running time cost in the time it takes to follow the vptr and access the vtable.
C++ Philosophy: Don’t pay for costs unless you ask for it.
Destructors revisited
class X {
int* a;
public:
X(int n): a{new int[n]}{}
~X() { delete[] a; }
};
class Y: public X{
int* b;
public:
Y(int n, int m): b{new int[m]}{}
~Y() { delete[] b; }
};
X x{5};
X* px = new X{5};
Y y{5,10};
Y* py = new Y{5,10};
X* pxy = new Y{5,10};
delete px; delete py; delete pxy;Which of these leaks memory?
Object destruction sequence:
- Destructor body runs
- Object fields have their destructors run in reverse declaration order
- Superclass destructor runs
- Space is reclaimed
Because the destructor is non-virtual, for pxy, we invoke ~X, not the ~Y, so this array b is leaked.
Solution: declare virtual ~X(), so delete pxy calls ~Y().
Unless you are sure a class will never be subclassed, then always declare your destructors as Virtual Destructors.
If you are sure, enforce it via the final keyword.
class X final {
... // Program won't compile if anyone tries to subclass X
}Lecture 11
- ooh this is interesting
class Shape {
public:
virtual float getArea() const;
};
class Square: public Shape {
float length;
public:
Square(float length): length{length} {}
float getArea() const override {
return length * length;
}
};
class Circle: public Shape {
float radius;
public:
Circle(float radius): radius{radius} {}
float getArea() const override {
return pi * radius * radius;
}
};If we do not provide an implementation for Shape::getArea(), code won’t link: “undefined reference to vtable error”
We could make Shape::getArea() return 0 or -1 to indicate “no area”, but it’s not natural. Really, we want to avoid a definition for Shape::getArea() entirely.
Solution: Declare Shape::getArea as a Pure Virtual Method. A pure virtual function is allowed to not have an implementation.
class Square {
public:
virtual float getArea() const = 0;
};Classes that declare a pure virtual function are called Abstract Class. Abstract classes cannot be instantiated as objects.
A class that overrides all of its parents pure virtual functions is called a Concrete Class. Concrete classes can be instantiated.
Purpose of abstract classes is to provide a framework to organize and define subclasses.
class Vec2 {
int x,y;
public:
Vec2(int x, int y): x{x}, y{y} {}
};
class Vec3: public Vec2 {
int z;
public:
Vec3(int x, int y, int z): Vec2{x,y}, z{z} {}
};
void f(Vec2* a) {
a[0] = Vec2{7,8};
a[1] = Vec2{9,10};
}
Vec3 myArray[2] = {Vec3{1,2,3}, Vec3{4,5,6}};
f(myArray);What does f expect:
a[0]. a[1] ...
[x, y, x, y, ]
What it actually looks like:
a[0]. a[1] ...
[7, 8, 9, 10, 5, 6]
Data ends up misaligned. All of Vec2{7,8} is written into myArray[0]. Half of Vec2{9,10} is written into myArray[0], the other half is in myArray[1].
Lesson
Be very careful when using arrays of objects polymorphically. Solutions:
- Use an array of pointers:
Vec3* myArray[2]- Use a vector of
Vec3*
How does an array of pointers fix the issue?
?
Polymorphic Big Five
Let’s consider Book hierarchy again.
Text t{"polymorphism", "Ross", 500, "C++"};
Text t2{t};Compiler still provides us a copy constructor, that works as expected.
Let’s look at copy/move constructor and assignment operator too. See their definition:
Text::Text(const Text& t): Book{b}, topic{t.topic}{}- Calls the copy constructor for the book pattern of Text.
tis aconst Text&, this is implicitly converted to aconst Book&.
Move Constructor:
Text::Text(Text&& t): Book {std::move(t)}, topic{std::move(t.topic)} {}t and t.topic are lvalues, so we’d invoke the copy ctor if we didn’t use std::move.
t is an rvalue reference so we know it is safe to steal title, author, length and topic via using std::move to invoke move constructors.
Copy Assignment:
Text& Text::operator=(const Text& t) {
Book::operator=(t); // calls the Book assignment operator for the book portion of this
topic = t.topic;
return *this;
}Move Assignment:
Text& Text::operator=Text(&& t) {
Book::operator=(std::move(t));
topic = std::move(t.topic);
return *this;
}All of these implementations are what the compiler gives by default. Customize as necessary - for example, if doing manual memory management, you will need to write your own versions of these.
BUT: Are the compiler provided definitions actually that good?
Text t1{"polymorphism", "Ross", 500, "C++"};
Text t2{"programming for babies", "LaurierProf", 100, "Python"};
Book& br1 = t1;
Book& br2 = t2;
br2 = br1;
cout << t2;- Title, author and length are set, but topic remains unchanged.
Book::operator= is defined as non-virtual. We’re calling operator= method on a reference. We use the static type, call Book::operator=, even though br1 and br2 are referencing texts.
Some fields are copied, but not all. This is the partial assignment problem.
How to fix this? Declare Book::operator= as virtual!
class Book {
...
public:
...
virtual Book& operator=(const Book& other) {
...
}
};Our usual signature for Text is the following
Text& operator=(const Text& other);Can we just slap an override on the end of this? NO: Signatures don’t match in 2 places: return type, parameter type.
- Return type: this is actually okay: A subclass’s override method can return a subclass of the virtual function’s return type (if it’s a pointer or reference)
- Parameter type for overridden functions must match exactly.
Signature must be the following
Text& Text::operator=(const Book& other) {
...
}Problem 1) can’t access other’s topic, because it’s a Book, and Book don’t have topics, only Texts do.
Problem 2) other is a Book&, so now this is legal:
Comic c{...};
Text t{...};
t = c;We can set a Text to a Comic, Comic on RHS can be implicitly converted to a const Book&.
This is the mixed assignment problem, which is where you can set subclass siblings to each other.
Non-virtual operator = leads to partial assignment virtual operator = mixed assignment
To fix this, restructure the Book hierarchy:
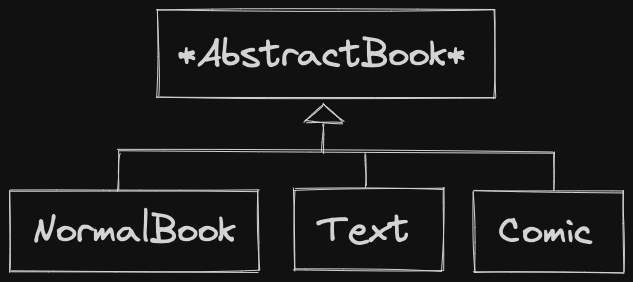
Lecture 12
class AbstractBook {
string title, author;
int length;
protected:
AbstractBook& operator=(const AbstractBook& other) = default;
public:
AbstractBook(...) {}
virtual ~AbstractBook() = 0;
};To make this abstract, we need a Pure Virtual Method. If no other methods make sense to be pure virtual, can always use destructor.
class Text: public AbstractBook {
string topic;
public:
Text(...) {...}
// implicitly: this is implemented: Text& operator=(const Text& t);
};How does this fix the two problems?
- Mixed assignment:
operator=is non-virtual and the implicitly provided copy assignment operator only acceptsText. - Partial assignment problem:
Text t1{...};
Text t2{...};
AbstractBook& br1 = t1;
AbstractBook& br2 = t2;
br2 = br1; //doesn't compile, AbstractBook:operator= is protectedNote: Only works since AbstractBook is an abstract class.
If we set Book::operator= to protected then we couldn’t assign books to one another.
Consider Text’s destructor. Implicitly, following happens:
- Destructor body runs (empty)
- Object fields we destructed in reverse decl. order
- Superclass destructor runs
- Space is reclaimed
Because in step 3, Text’s destructor calls AbstractBook’s destructor, we have a problem: we’ve called a method with no implementation.
Solution: give it an implementation:
AbstractBook::~AbstractBook(){}Pure Virtual Methods can STILL be implemented in the base class
Pure virtual methods don’t have to be implemented, but they still can be. They require an implementation if they will be called.
”= 0 means derived classes must provide an implementation, not that the base class cannot provide an implementation”. See this StackOverflow thread.
AbstractBook is still abstract, only subclasses of classes which define a pure virtual method may be concrete.
One possible recommendation: If you care about assignment, consider making your superclasses abstract.
Error Handling
Example from STL vector.
Vectors: dynamically allocated resizing arrays. Handles memory management so we don’t screw it up.
Unfortunately, can’t idiot proof everything.
vector<int> v;
v.push_back(100);
cout << v[100] << endl; // out-of-bounds access, likely seg faultHow to handle errors:
Option 1: Sentinel values. Reserve some values, -1, INT_MIN to signal errors
- Problem: reduces what we can return, can’t return -1 in a regular scenario. Not clear for a general type T what values we should pick as sentinels.
Option 2: global variables. Create some global variable that is set when an error occurs (in C,
int errno, which can be queried for errors with standard functions). - Also not idea: limited # of errors, might be overwritten Option 3: Bundle in a struct:
template<typename T> struct ReturnType {
int errorcode;
T* data;
}Best so far, but still not ideal. Wrap our return types in this struct, all return types are larger than needed. Awkward to access data field.
These are all approaches that C users end up using. C++ however has a language feature for dealing with errors: Exceptions.
V.at(100) fetches V[100] if the value exists, otherwise, throws an exception.
try {
cout << v.at(100) << endl;
} catch(std::out_of_range r) {
cout << "Range error" << r.what() << endl;
}ris just an object, class type isstd::our_of_range(included in<stdexcept>)- The
.what()method returns a string describing the exception.
Force the programmer to deal with the error because the control flow jumps.
Vector knows the error happened but not how to fix it.
We know how to fix it, but not how the error occurred
- non-locality of error handling
To raise an exception ourself, we use the throw keyword. We can throw any value, but keep in mind that <stdexcept> has objects for common scenarios like out_of_range, logic_error, invalid_argument.
When an exception is raised, control flow steps. We search through the stack upwards looking for a handler for this type of exception. This is called Stack Unwinding. Destructors are run for objects stored on the stack during the process of stack unwinding. If a handler is found, we jump to that point. If no handler is found, program crashes.
Example:
void f() {
throw std::out_of_range{"f threw"};
}
void q() { f();};
void h() {q();};
int main() {
try { h();}
catch (std::out_of_range r) {
cout << r.what();
}
}- Main calls
h,hcallsq,qcallsf, throws, stack unwinding throughq,h, jump to catch block in main.
Multiple errors may be handled via multiple catch blocks.
try {...}
catch (out_of_range r) {...}
catch (logic_error e) {...}
catch (invalid_argument u) {...}
catch(...) {...} // yes, catch(...) is the catch-all syntax which catches any type of exception . Literally 3 dotsOne handler can also deal with part of an error, rethrow the exception to allow someone else to deal with it.
void calculation(DataStructure& ds) {
...
throw (ds_error) {...};
}
void DataStructureHandler(DataStructure& ds) {
try {calculation(ds);}
catch (ds_error e) {
// fix the data structure issue
throw prompt_input_error{...};
}
}
int main() {
DataStructure ds;
string s;
while (cin >> s) {
try {
DataStructureHandler(ds);
} catch (prompt_input_error e) {
cout << "invalid input";
}
}
}Lecture 13
In the last lecture, we saw that we can throw different types of exceptions from catch blocks. We can also rethrow the same exception for someone else to deal with.
try {...}
catch (std::exception& e) {
...
throw;
}Why here do I just say throw rather than throw e?
throw eperforms a copy in order to throw this exception- Remember that copy constructors (any type of constructor) cannot be virtual. Therefore, the static type is used for the copy
If you throw a range_error and catch via std::exception& catch block,
throwrethrowsrange_errorthrow ecatch astd::exceptioncopied from therange_error, we lose the dynamic type.
Generally, catch blocks should catch by reference to avoid avoid copies.
Never let a destructor throw an Exception!
Default behavior: Program immediately crashes.
noexcept is a tag associated with methods (like const), which states the method will never raise an exception, destructors are implicitly noexcept tagged.
We can allow exceptions thrown from destructors by tagging them noexcept (false).
For example,
class A {
public:
...
~A() noexcept (false) {...}
}Danger
If we throw an exception, Stack Unwinding occurs, during this process destructors are running for stack allocated objects. If one of these destructors throws, now we have 2 active exceptions!
- 2 active exceptions = program crash (this behavior cannot be changed)
Exception Safety
void f() {
MyClass m;
MyClass* p = new MyClass{};
g();
delete p;
}Under normal circumstances, f does not leak memory. But, if g throws, then we do not execute delete p, so we do leak memory!
Thing to recognize: exceptions significantly change control flow! We no longer have the guarantee of sequential execution.
Let’s fix f, so we can handle its memory leak.
void f() {
MyClass m;
MyClass* p = new MyClass{};
try {
g();
} catch (...) {
delete p;
throw;
}
delete p;
}Complaints about the fix above:
- Repeated code.
delete ptwice, little annoying - Could get complicated for many pointers, many function calls, etc.
In other languages, some have “finally” clause, which always runs, either after a successful try, a successful catch, or before a catch returns. Unfortunately, C++ doesn’t have support for this.
- The only guarantee is that during Stack Unwinding, stack allocated objects have their destructors run.
- Therefore, use stack allocated objects instead no leak
What if we need a pointer? For example, to achieve Polymorphism
One solution: wrap the pointer in a stack allocated object that will delete it for us during stack unwinding.
C++ Idiom: RAII (resource acquisition is initialization)
Example:
{
ifstream file{"file.txt"};
...
}Resource (file handler) is acquired in the constructor (initialization). Resource is freed (closing the file) in the destructor.
Apply this RAII concept to dynamic memory.
std::unique_ptr<T> (in <memory> library), i.e. Unique Pointers
- contains a
T*passed via the constructor - deletes the
T*in the destructor
void f() {
MyClass m:
std::unique_ptr<MyClass> p{new MyClass{}};
g();
}If we leave f normally, or if we leave f during stack unwinding, either way, p’s destructor runs, deletes heap memory.
In between, we can use p like a regular pointer thanks to operator overload.
Generally, we do not call the constructor directly with a pointer, because of the following issues:
std::unique_ptr<T> p{new T{}};new is not paired with a delete (not one that we see, at least)- Causes a double delete:
T* p = new T{};
std::unique_ptr<T> w{p};
std::unique_ptr<T> r{p};g()can potentially throw in the example below, heap-allocated object does not get deleted
f(std::unique_ptr<T> {new T()}, g());One potential ordering (in C++14) (obscure scenario)
new T()g()unique_ptrconstructorf()
Preferred alternative: std::make_unique<T> (…)
- Constructs a
Tobject in the heap with arguments …, and returns aunique_ptr<T>pointing at this object.
Something else to consider:
unique_ptr<T> p = make_unique<T>(...);
unique_ptr<T> q = p;Call copy constructor to copy p into q.
What happens? Doesn’t compile. Copying is disabled for unique_ptrs. They can only be moved.
This is achieved by setting copy constructor / assignment operator to = delete.
unique_ptr are good for representing ownership, since when one object dies, its unique_ptr fields will run and clean up the associated object.
Has-a relationship: Use raw pointers or references.
- You can access the underlying raw pointer of a smart pointer via
.get().
Lecture 14
What if we want shared ownership, where some memory is deleted only if all the pointers pointing to it are deleted?
We can achieve this via std::shared_ptr<T>, i.e. Shared Pointers.
shared_ptr maintains a reference count, which keeps track of how many shared pointers point at this memory. When it hits 0, memory is freed.
class C {
// replace ... with args to create a C object
shared_ptr<C> p = make_shared<C>(...);
if (...) {
shared_ptr<C> q = p;
} // destructor for q runs, reference count is 1
...
} // dtor for p runs, ref count is 0, C object is deletedThere are still problems with shared_ptrs:
- Susceptible if you use the constructor
C* cp = new C{...};
shared_ptr<C> p{cp}; // Incorrect
shared_ptr<C> q{cp}; // Double deleteqhas no knowledge ofp’s existence
- Cyclical reference issue
- If we have multiple shared ptrs that point at each other, we have the issue that some pointers may never be deleted
class Node {
shared_ptr<Edge> myEdges;
shared_ptr<Node> neighbors;
}
full example through ChatGPT
class Node {
public:
shared_ptr<Node> next;
};
int main() {
shared_ptr<Node> node1 = make_shared<Node>();
shared_ptr<Node> node2 = make_shared<Node>();
// Create a cyclical reference
node1->next = node2;
node2->next = node1;
return 0;
}In general, shared ownership is somewhat rare. Take care in constructing your programs. Usually, it suffices to use the following:
unique_ptror object field - ownership / Composition- raw pointer or reference - Aggregation (“has-a”)
shared_ptr- shared ownership
Exercise: Implement shared_ptr.
We’ll come back to exception safety later.
- Provide some standard “good” solution to a common problem
- One common problem: adding / removing behavior at run-time with a polymorphic class.
- One example: Windowing system - GUI.
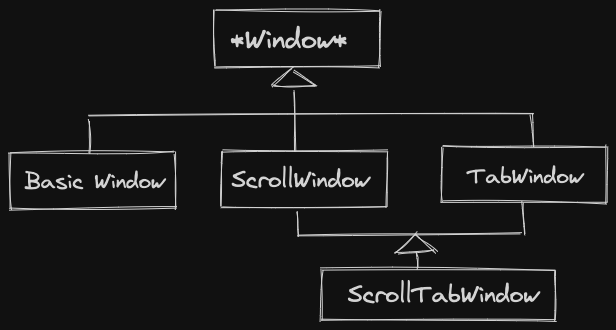
If we attempt to make a class for each possible feature, for features, there are possible configurations. Combinatorial explosion!
Solution: Decorator Pattern (Linked List of functionalities)

Pieces of the decorator pattern:
- Abstract Component: Gives the interface for our classes
- Concrete Component: Implements the “basic” version of the interface
- Abstract Decorator: Organizes decorators and has-a decorator or the concrete component.
- Concrete Decorators: Implement the interface, call
operation()on the next object in this linked list.
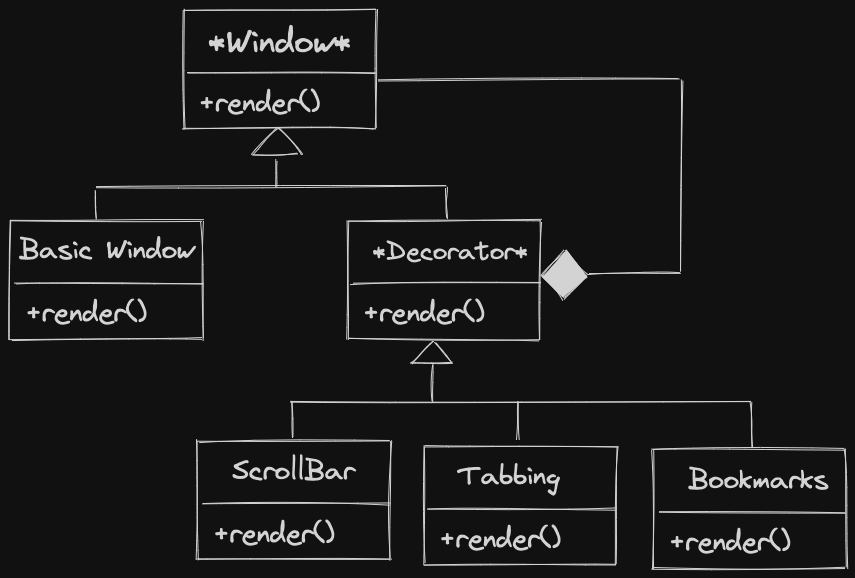
Window* w = new ScrollBar{new Tabbing{new BasicWindow{}}};ScrollBar Tabbing Basic Window
w->render()Example: Pizza
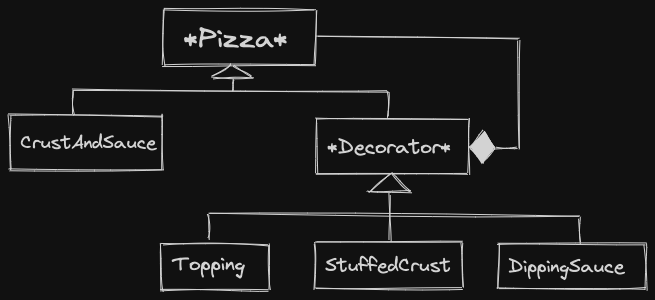
class Pizza {
public:
virtual ~Pizza(){}
virtual float price() const = 0;
virtual string desc() const = 0;
};
class CrustAndSauce: public Pizza {
public:
float price() const override {return 5.99;};
string desc() const override {return "pizza";};
};
class Decorator: public Pizza {
protected:
Pizza* next;
public:
Decorator(Pizza* next): next{next} {}
~Decorator() {delete next;}
};
class Topping: public Decorator {
string name;
public:
Topping(const string& s, Pizza* p): Decorator{p}, name{s} {}
float price() const override {
return 0.75 + next->price();
}
string desc() const override {
return next->desc() + " with" + name;
}
};
class StuffedCrust: public Decorator {
public:
StuffedCrust(Pizza* p): Decorator{p} {}
float price() const override {
return next->price() + 2.50;
}
string desc() const override {
return next->desc() + " with stuffed crust";
}
};
Pizza* p = new CrustAndSauce{};
p = new Topping{"cheese", p};
p = new Topping{"pepperoni", p};
p = new StuffedCrust{p};
cout << p->price() << " " << p->desc() << endl;
// 9.99 pizza withcheese withpepperoni with stuffed crust
delete p;StuffedCrust Topping Topping CrustAndSauce
Lecture 15
Observer Pattern: Publisher / Subscriber relationship.
Publisher: Generates some data, change in state Subscriber: Can dynamically subscribe or unsubscribe for various publishers. Should react when data is changed.
Example: Spreadsheet application:
- Publishers: Cells (Subjects)
- Subscribers: Charts (Observers)
When a cell changes, charts that are observing that cell must re-render, display new information.
May have different types of publishers / subscribers, e.g. - different charts require different logic for re-rendering.
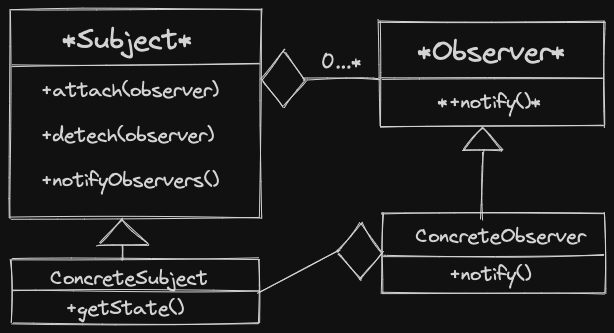
Steps
ConcreteSubjecthas its state updatednotifyObserversis called - either byConcreteSubjector some controller (like themainfunction)- notify is called on each observer in Subject’s observer list
- This calls
ConcreteSubject::notify, by the assumption it is pure virtual ConcreteObservercallsgetStateonConcreteSubject, uses info as necessary
Example: Twitter clone. Tweeters are subjects. Followers which are observers, can only follow one tweeter.
#include <vector>
#include <string>
#include <iostream>
#include <fstream>
using namespace std;
class Observer {
public:
virtual void notify() = 0;
virtual ~Observer() {};
};
class Subject {
vector<Observer*> observers;
public:
void attach(Observer* ob) { observers.emplace_back(ob); }
void detach(Observer* ob) { /* Unfollowing todo */ }
void notifyObservers() {
for (auto ob: observers) ob->notify();
}
virtual ~Subject() = 0;
};
Subject::~Subject() {}
class Tweeter : public Subject {
ifstream in;
string lastTweet;
public:
Tweeter(const string& source): in{source} {}
bool tweet() {
getline(in, lastTweet);
return in.good();
}
string getState() { return lastTweet; }
};
class Follower : public Observer {
Tweeter* iFollow;
string myName;
public:
Follower(Tweeter* iFollow, string myName): iFollow{iFollow}, myName{myName} {
iFollow->attach(this);
}
void notify() {
string lastTweet = iFollow->getState();
if (lastTweet.find(myName) != string::npos) {
cout << "They said " << myName << ", that's my name!" << endl;
} else {
cout << "They didn't mention me, " << myName << endl;
}
}
};
int main() {
Tweeter elon{"elon.txt"};
Follower joe{&elon, "joe"};
Follower wario{&elon, "wario"};
while (elon.tweet()) {
elon.notifyObservers();
}
}Important Note
Notice that this only works because destruction happens in reverse order!
Wait, I’m slightly confused, why does it work? Why doesn’t the program leak memory here? Ahh, I think if you had something like declaring
Followerfirst, then declaringTweeter, you would get memory leak, because theTweeterwould get destroyed first. But that is not the case here,Followers gets destroyed first, thenTweeter. See Destructor.
Also note: The design patterns we demonstrate here are simplistic implementations. Only get value at scale - multiple types of subjects / observers.
Other variants also exist - for example, passing a Subject& via notify method.
Casting allows us to take one type, treat as another.
In C:
Node n;
int* ip = (int*) &n; // (int*) is the casting operator - treat this as an int*This is dangerous, generally avoid casting unless necessary, subverts type system. If necessary, use one of the 4 C++ casts instead of C-style casting.
static_cast- “well-defined” conversions between two types
void g(float f);
void g(int n);
float f;
g(static_cast<int>(f));gcallsintversion ofg
Another example:
Book* b = ...;
Text* t = static_cast<Text*> (b);- “trust me bro, I know it’s a Text”
- Undefined behavior if it’s not actually pointing at a
Text
reinterpret_cast- allows for poorly defined implementation dependent casts. Most uses ofreinterpret_castare undefined behavior.
Rational r;
Node* n = reinterpret_cast<Node*>(&r);Lecture 16
const_cast- the only type of cast that can “remove” constness. Example: using some library that gives us:
void g(int* p);Let’s say we know g doesn’t modify the int pointed to by p in any way. Also, I have a const int* I’d like to call g with. Compiler will prevent us from calling g, because it might modify p.
I can use const_cast to call g in the following way:
void f(const int* p){
g(const_cast<int*> p);
}Generally, const_cast should be avoided.
Another example, working on legacy codebase that doesn’t use const anywhere. We want to add consts, make our program const-correct.
Issue: const-poisoning. Adding const in one location often means we must add it to other locations to allow it to continue to compile.
We can use const-cast to bridge between const-correct and non-const-correct parts of our program. Make small independent parts of the program const-correct, use const-cast to allow the program to compile as the work is done.
dynamic_cast: used for safely casting between pointers/references in an inheritance hierarchy
Book* pb = ...;
static_cast<Text*>(pb)->getTopic();Only safe if pb actually points to a Text.
Instead,
Book* pb = ...;
Text* pt = dynamic_cast<Text*>(pb);if the cast succeeds (i.e. dynamic type is Text), then pt points at the Text. Otherwise, pt is set to nullptr.
if (pt) cout << pt->getTopic();
else cout << "Not a Text!";Also can be used on references.
Text t{...};
Book& br = t;
Text& tr = dynamic_cast<Text&>(br);What if br is actually referencing a Comic? Cannot set it to null, no such thing as a null reference.
If dynamic_cast fails with a reference: throw a std::bad_cast exception.
There exist smart pointer versions of each of these casts:
static_pointer_cast
const_pointer_cast
dynamic_pointer_castCast shared_ptrs to other shared_ptrs.
Those allow us to make decisions based on RTTI (Run-Time Type Information).
void whatIsIt(shared_ptr<Book> b) {
if (dynamic_pointer_cast<Text>(b)) cout << "Text";
else if (dynamic_pointer_cast<Comic>(b)) cout << "Comic";
else cout << "Normal Book";
}BAD
The above function is poor object-oriented design. Don’t do this.
Also Note: dynamic_cast only works if you have at least one virtual method.
Recall: polymorphic assignment problem. We considered making operator= virtual.
- operator= non-virtual: partial assignment
- operator= virtual: mixed assignment
Text t1, t2;
Book& b1 = t1;
Book& b2 = t2;
b1 = b2;Let’s make operator= virtual in Book.
Text& Text::operator=(const Book& other) {
// line below throws if `other` is not a Text
Text& tother = dynamic_cast<const Text&>(other);
if (this == &tother) return *this;
Book::operator=(other);
topic = tother.topic;
return *this;
}Measures of Design Quality
Question: How can we evaluate the quality of our code - what is good, what is bad, when we’re not just following a particular design pattern?
We’ll discuss a number of ways:
- code smells - refactoring
- coupling / cohesion - how do my classes interact?
- SOLID design principles
Coupling: Description of how strongly different modules depend on one another.
Low Coupling:
- Function calls with primitive args / results
- Function calls with structs / arrays as results
- Modules affect each other’s control flow
- Modules sharing global data
High Coupling:
- Modules have access to each other’s implementation (friend)
Ideally, we desire low coupling:
- easier to reason about our program
- easier to make changes
We can cheat: If I put everything in one class, super low coupling!
Counterbalancing force: Cohesion - how closely do the parts of my module relate to one another?
Low Cohesion:
- parts of module are completely unrelated, e.g.
<utility>
module has a unifying common theme, e.g. <algorithm>
Elements manipulate state over lifetime of an object, e.g.<fstream>
High Cohesion:
- Elements are cooperating to perform exactly on task
Cheat at Cohesion:
- put every function in its own class, then they each do only one thing!
The Goal
We strive for: low coupling, high cohesion.
Ex: whatIsIt function - exhibits high coupling with the Book hierarchy.
Any new classes in Book hierarchy necessitate changes to this function.
SOLID Design Principles Acronym of 5 principles: purpose is to reduce software rot (the property that long lasting codebases become more difficult to maintain)
- Single Responsibility Principle
- Open-Closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
Single Responsibility Principle “A class should only have one reason to change”.
i.e. a class should do one thing, not several.
A change to a program spec requires a change to the source code.
If changes to different parts of the spec require changes in the same class, then SRP is violated.
Example: Consider ChessBoard Class.
class ChessBoard {
...
... cout << "Your Move";
};This is actually somewhat bad design. ChessBoard should not print to the screen.
What if I instead want to print to a file? Cannot use the same class without replacing couts with printing to a file.
class ChessBoard {
ostream& out;
istream& in;
public:
ChessBoard(ostream& out, istream& in): out{out}, in{in} {}
...
...
out << "Your Move";
};Little more flexible, but still has issues.
What if we want a graphic display? Or to change the language, or to communicate over the internet?
We have low cohesion, violating SRP. ChessBoard is doing multiple things: manipulate state, implement logic, control rendering to the screen.
Instead: chessBoard should communicate via results, parameters, exceptions. Allow other classes to handle communication with the user.
Lecture 17
Should main be performing communication?
No - limits reusability.
Another possibility: Use the MVC architecture, well-suited for SRP.
MVC: Model-View-Controller.
- Model: Handles logic + data
- View: Handles program output / display
- Controller: Handles input, facilitates control flow between classes
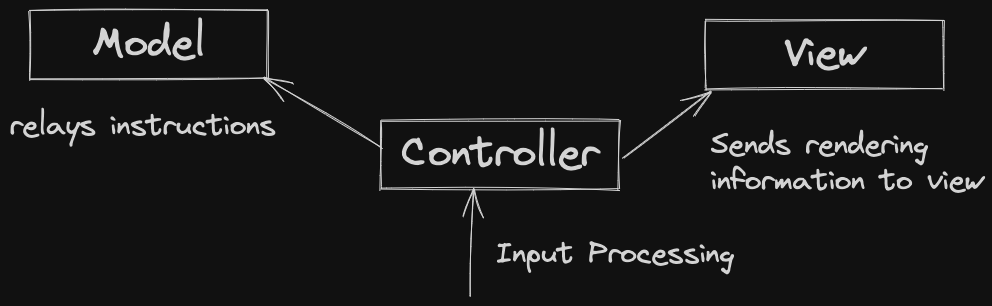
Model: May have multiple views, or just one - different types of views: text, graphical view, etc.
- Model doesn’t need to know anything about the state / implementation of the views
- Sometimes we structure interactions between Model and View as an Observer Pattern
Controller: mediates control flow.
- May encapsulate things like turn-taking or some portion of the game rules.
- Some of this logic may go in the model instead: judgement call
- May communicate with user for input (sometimes done by the View)
By decoupling presentation, input, and data/logic, we follow SRP, and promote re-use in our programs.
On the other hand, there may be parts of the specifications that are unlikely to change, and so adding layers of abstraction just to follow SRP may not be worthwhile.
Avoiding needless complexity is also worthwhile - use your best judgement.
Classes should be open to extension, but closed to modification.
Changes to a program should occur primarily by writing new code, not changing code that already exists.
Example

- What if we wanted our
Heroto use a different type of weapon?BoworMagicWand? - Requires us changing all the places we referenced the
Swordclass - lots of modifications, not much extension.
Fix is to use Strategy Pattern:
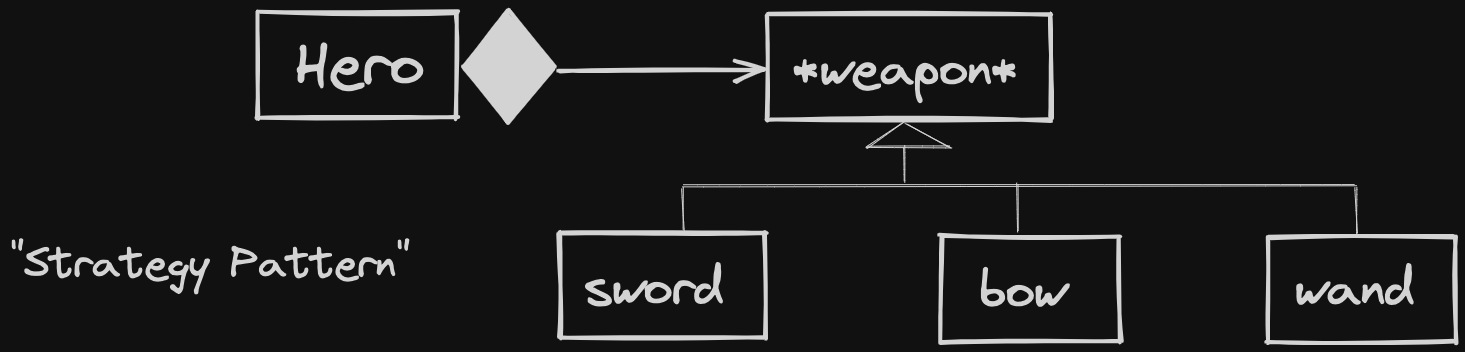
Open-Closed Principle: Closely related to the concept of inheritance and virtual functions.
For example:
int countHeavy(const vector<Book*>& v) {
int count = 0;
for (auto p: v) {
if (p->isHeavy()) ++count;
}
return count;
}This function is open to extension: we can add more functionality by defining new types of Books, and closed to modification: countHeavy never needs to change now that it has been written.
Compare this to WhatIsIt:
- not open to extension: cannot get new behavior without modifying the source code
- not closed to modification either
Open/closed principle is an ideal - writing a program will require modifications at some point.
Plan for things that are most likely to change, account for those.
Enforces something discussed so far strictly:
- public inheritance should modael an is-a relationship
If class B inherits from class A: we can use pointers / references to B objects in the place of pointers / references to A objects: C++ gives us this.
Liskov Substitution is stronger: not only can we perform the substitution, but we should be able to do so at any place in the program, without affecting its correctness.
So precisely:
- If an invariance is true for class
A, then it should also be true for classB - If an invariant is true for method
A::f, andBoverridesf, then this invariant must be true forB::f - If
B::foverridesA::f- If
A::fhas a preconditionPand a postconditionQ, thenB::fshould have a preconditionP'such thatP=>P'and a postconditionQ'such thatQ'=>Q B::fneeds a weaker precondition and a stronger postcondition
- If
Ex: Contravariance problem
- Happens whenever we have a binary operator where the other parameter is the same type as
*this.
class Shape {
public:
virtual bool operator==(const Shape& other) const;
}class Circle: public Shape {
public:
bool operator==(const Shape& other) const override;
}As we’ve seen before, we must take in the same parameter when overriding. C++ enforces this, which actually enforces LSP for us.
- A
Circleis-aShape - A
Shapecan be compared with otherShapes - A
Circlecan be compared with any otherShape
To satisfy LSP, we must support comparison between different types of shapes.
bool Circle::operator==(const Shape& other) const {
if (typeid(other) != typeid(Circle)) return false;
const Circle& cother=static_cast<const Circle&>(other);
...
} typeidreturnsstd::type_info` objects that can be compared.
dynamic_cast: Is other a Circle, or a subclass of Circle?
typeid: Is other exactly a Circle?
typeid uses the dynamic-type so long as the class has at least one virtual method.
Ex: Is a Square a Rectangle?
4th Grader: Yes, a Square is a rectangle.
A square has all the properties of a rectangle.
class Rectangle {
int length, width;
public:
Rectangle(int l, int w): length{l}, width{w} {}
int getLength() const;
int getWidth() const;
virtual void setWidth(int w) {width=w;};
virtual void setLength(int l) {length=l;};
int area() const {return length * width;};
};
class Square: public Rectangle {
public:
Square(int s): Rectangle{s,s} {}
void setWidth(int w) override {
Rectangle::setWidth(w);
Rectangle::setLength(w);
}
void setLength(int l) override {
Rectangle::setWidth(l);
Rectangle::setLength(l);
}
};
int f(Rectangle& r) {
r.setLength(10);
r.setWidth(20);
return r.area(); // surely this returns 200
}
// But:
Square s{100};
f(s); // gives us 400Issue: we expect postcondition for Rectangle::setWith to be that the width is set and nothing else changes. Violated by our Square class.
Violates LSP, does not satisfy an is-a relationship. Conclusion: Square are not Rectangles.
Possibility: Restructure inheritance hierarchy to make sure LSP is respected.
In general: how can we prevent LSP violations?
- Restrain what our subclasses can do, only allows them to customize what is truly necessary.
We can use a design pattern: Template Method Pattern. We’ll provide a “structure” or “recipe” or “template” for what this method will do, allow subclasses to customize portions of this method by performing overrides.
General: When a subclass should be able to modify same parts of a method’s behavior, but not all.
Lecture 18
Template Method Design Pattern: In video game, I have two types of Turtles: RedTurtle + GreenTurtle.
class Turtle {
virtual void drawShell() = 0;
void drawHead() { 😄; }
void drawLegs() {🦵🦵🦵🦵; }
public:
void draw() {
drawHead();
drawShell();
drawLegs();
}
}
class RedTurtle: public Turtle {
void drawShell() override { 🔴; }
};
class GreenTurtle: public Turtle {
void drawShell() override { 🟢; }
};Note: draw method is public and non-virtual.
- Nobody who subclasses
Turtlecan overridedraw. GreenTurtleandRedTurtlecan define draw, but it won’t be an override, won’t be called if we useTurtles polymorphically
Note as well: drawShell is private, but we can still override it! Access specifiers only describe when methods can be called, not how they may be overwritten.
NVI - Non-Virtual Idiom
public virtual methods are trying to do two things at once:
- public: Providing an interface to the client
- will uphold invariants
- Respect pre-conditions / post-conditions
- expected to do its job
- virtual: providing an interface to subclasses
- Virtual methods are those that may be customized while an object is used polymorphically
- Provide “hooks” to allow customization of behaviour
Satisfying the responsibilities of “public” and “virtual” simultaneously is difficult
- How are we sure a public virtual method will satisfy its invariants, pre-conditions / post-conditions. Will it even do its job?
- What if we want to add more code to the public virtual method without changing the interface?
Non-Virtual Idiom states the following:
- All public methods are non-virtual
- All virtual methods should be private (or protected)
- Exception for the Destructor
Example: DigitalMedia
class Digitalmedia { // No NVI here
public:
virtual ~DigitalMedia() {}
virtual void play() = 0;
}With NVI:
class DigitalMedia {
virtual void doPlay() = 0;
public:
virtual ~DigitalMedia() {}
void play() {
doPlay();
}
}Now: We can add code that must run for all types of DigitalMedia before or after the doPlay call.
- we could copyright checking before
doPlay, this will always run - Or: update a play count after
doPlay- now subclasses don’t have to worry about maintaining this invariant
Flexible: can provide more “nodes” for customization simply by adding more private virtual method calls.
E.g.: showArt() before doPlay() - private virtual display poster for movie, album cover for song, etc.
All can be done without changing the public interface! Which is good for minimal recompilation, open / closed principle.
- In general, easier if we constraint what subclasses do from the beginning, as opposed to wresting back control. Supporting Liskov Substitution Principle
- Any decent compiler will optimize the extra function call out - so no cost at runtime
Interface Segregation Principle
- No code should depend on methods that it doesn’t use
- We prefer many small interfaces over one larger, more complicated interface
- If a class has many functionalities, each client of the class should only see the functionality that it needs
Example: Video Game (No NVI for simplicity)
class Enemy {
public:
virtual void strike(); // Used in the combat process
virtual void draw(); // Used by UI of our game
} ;
class UI {
vector<Enemy*> enemies; // All the enemeis the UI might need to draw
};
class Battlefield {
vector<Enemy*> enemies; // All the enemies that might perform combat
};Imagine we make a change to our drawing interface
battlefield.ccmust still recompile, even though it’s not using any part of the drawing interface- Needless coupling between UI and Battlefield via Enemy
One solution: Multiple Inheritance
class Enemy: public Draw, public Combat {};
class Draw {
public:
virtual void draw() = 0;
};
class Combat {
public:
virtual void strike() = 0;
};
class UI {
vector<Draw*> enemies;
}
class Battefield {
vector<Combat*> enemies;
}
Somewhat similar to the Adapter Pattern - used when a class provides an interface different from the one you need.
For example - Library for our window - expects objects to inherit from “Renderable” and provide a “render” method.
Don’t want to change all of our inheritance hierarchy, or all our draw calls to render - violates open / closed, pain. Use an adapter class.
- Satisfy the
Renderableinterface by calling the methods we’ve already defined. - We might not even need our Adapter to provide this “draw” method anymore, just render. In which case, we could use private inheritance.
What is private inheritance?
class A {
int x;
protected:
int y;
public:
int z;
};Under protected inheritance: class B: protected A {...}
Xremains inaccessibleYremains protectedZbecomes protected: can only be accessed inBand subclasses ofB
Under private inheritance: class B: private A {...} or class B: A {...}
Xremains inaccessibleYandZbecome private: Can only be be accessed inBmethods
Protected and private inheritance are not is-a (Specialization) relationship.
Lecture 19
As such, we cannot use classes with private or protected inheritance polymorphically.
A* p = new B{...}; // only legal under public inheritanceMultiple inheritance can have some tricky semantics.
class A1 {
public:
void foo() {cout << "A1::foo" << endl;};
};
class A2 {
public:
void foo() {cout << "A2::foo" << endl;};
}
class B: public A1, public A2 {}
B b{};
b.foo(); //what should happen?Ambiguous - it’s not clear whether A1::foo or A2::foo should be called - b.foo() doesn’t compile. Disambiguate: b.A1::foo() or b.A2::foo()
Question
Can you do this if
binherits from a single class, sayclass B: public A, can you doB.A::foo()?Although not needed, yes you can do this! It’s using the Scope Resolution Operator.
Another tricky aspect of multiple inheritance - shared base class. ”Diamond Problem”, “deadly diamond of death”.
struct A {int a = 1;}
struct B: A{};
struct C: A{}; // Don't need to specify public - structs have public inheritance by default
struct D: B, C{};
D dobj;
dobj.a = 2; // Doesn't compile eitherBecause a D is-a B and a C, it ends up having 2 a fields - one from the B portion of the object and one from the C portion of the object.
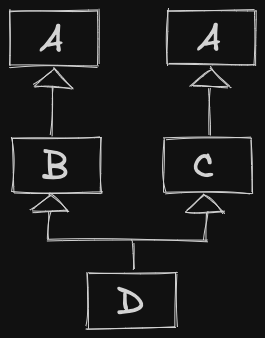
Must instead disambiguate - which a field are we talking about? The one from the B portion or the one from the C portion?
dObj.B::a = 1 // setting different a fields in the D object
dObj.C::a = 2;What if we wanted to disable this (somewhat strange) behaviour, and have only copy a A in our hierarchy? Solution: Use Virtual Inheritance.
struct B: A -> struct B: virtual A {...}
class C: public A -> class C: virtual public A {...}The keyword “virtual” indicates that this base class will be shared among all others who inherit from it virtually in the inheritance hierarchy.
Now, dOjb.a unambiguous, a field is now shared between both patterns of the object.
class A {
public:
A(int x) {...}
}
class B: public virtual A {
public:
B(...): A{1} ... {}
};
class C: public virtual A {
public:
C(...): A {2} {...}
};
class D: public B, public C {...}Constructors for virtual bases must run before any other constructors.
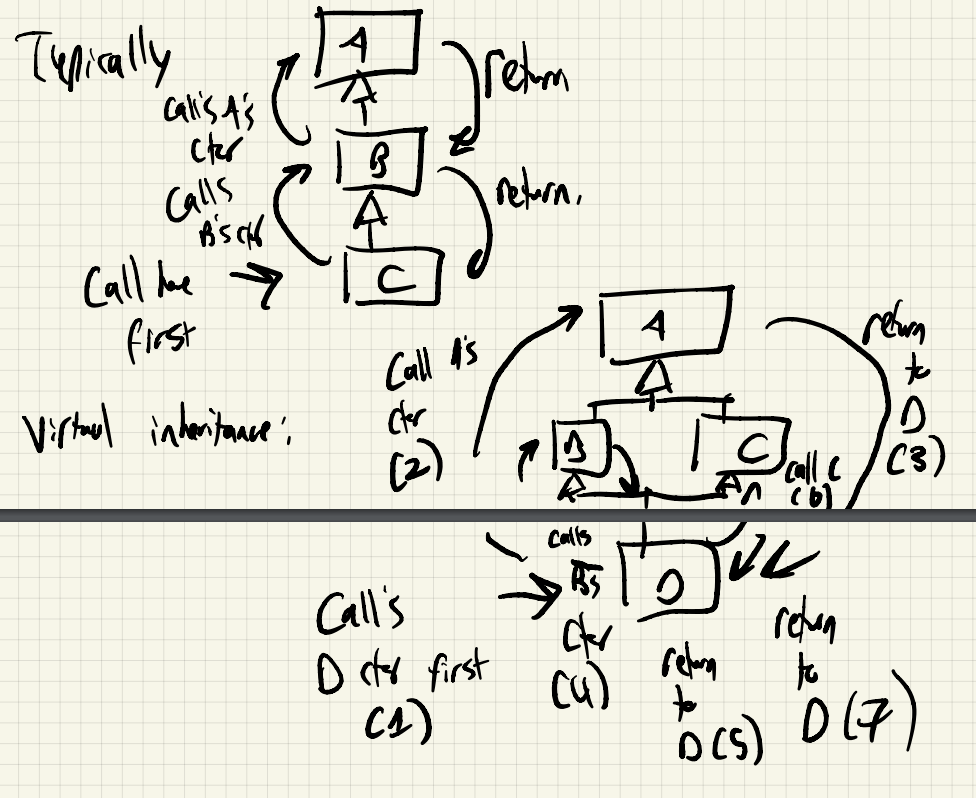
- This shows the order in which the objects is constructed for virtual inheritance
Fixed
class A {
public:
A(int x): ... {...}
};
class B: public virtual A {
public:
B(): ... {...} // Calls A's ctor
};
class C: public virtual A {
public:
C(): ... {...} // Calls A's ctor
};
class D: public B, public C {
public:
D(): A{5}, B{}, C{} ... {...}
};What about object layout with multiple virtual inheritance???
class A {...}
class B: public A{...}B object:
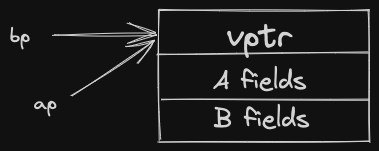
B* bp = new B{...};
A* ap = bp;To treat a B* like an A*, simply create a pointer copy, points at the same location, ignore B fields. Same strategy cannot be used for multiple virtual inheritance.
D* dp = new D{...};
A* ap = dp;
B* bp = dp;
C* cp = dp; // Doesn't look like a Cobject if we point at the same location!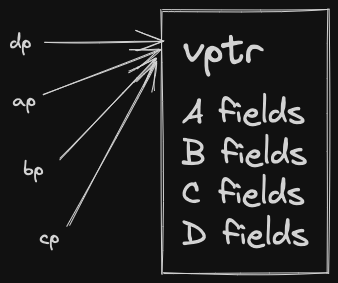
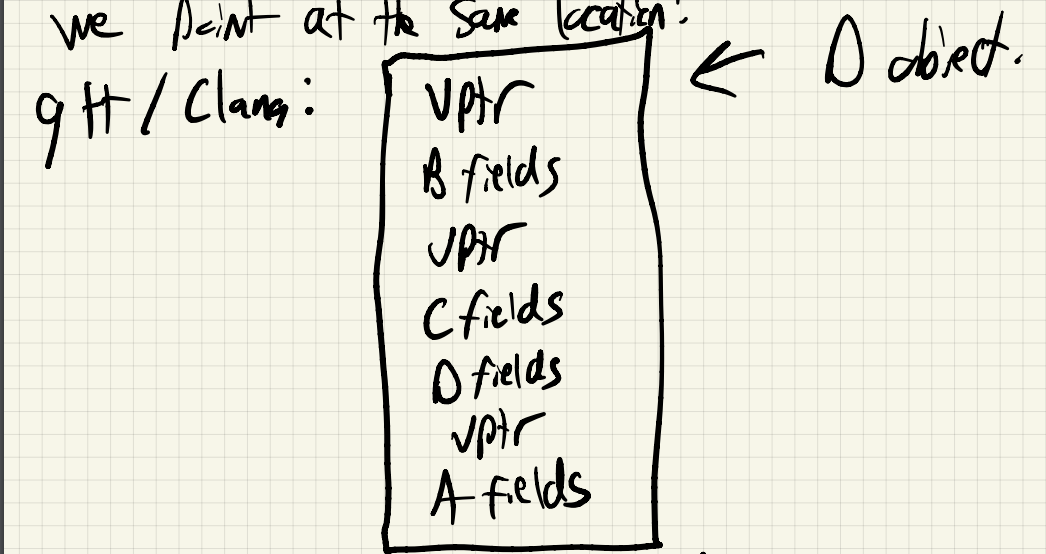
Note
virtual Base(A)is actually stored at the end of the object! Not the beginning.
B* bp = ...;
cout << bp->a << endl;If bp points at a D object, see above memory diagram.
If bp points at a B object,
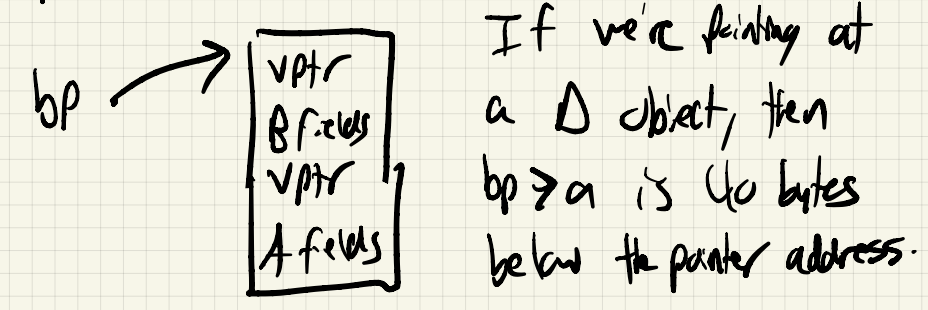
If we’re pointing at a B object, bp->a is 24 bytes below the pointer address.
Note: Now, finding superclass fields depends on the dynamic type.
Solution: Store the offset to the superclass fields inside of the vtable.
This is where the new “virtual” inheritance comes from.
Note: The D object does not look like an A object, a C object, or a D object simultaneously, but portions of it do.
Doing pointer assignment can change where the pointer is pointing to.
- This is really IMPORTANT, be careful
D* dp = new D{...};
A* ap = dp; // dp points at the top of the D object
// ap points just at the t positionstatic_cast/dynamic_castwill also adjust pointer locations for you as necessary.reinterpret_castwon’t - underscores danger associated with the cast.
Finally, both Google C++ Style guide, and ISOCpp both recommend when using multiple inheritance, Interface Classes are best.
Interface classes are those that:
- Define all methods as pure virtual
- Contain no state (fields)
Lecture 20
Dependency Inversion Principle: High level modules should not depend on low-level modules - instead, only should depend on an abstraction.
Abstract classes should not depend on concrete classes.
Example: Microsoft word. Word Counter rely on some sort of keyboard input. Breaks dependency inversion principle because counting words is “high level”, getting input “low-level”.
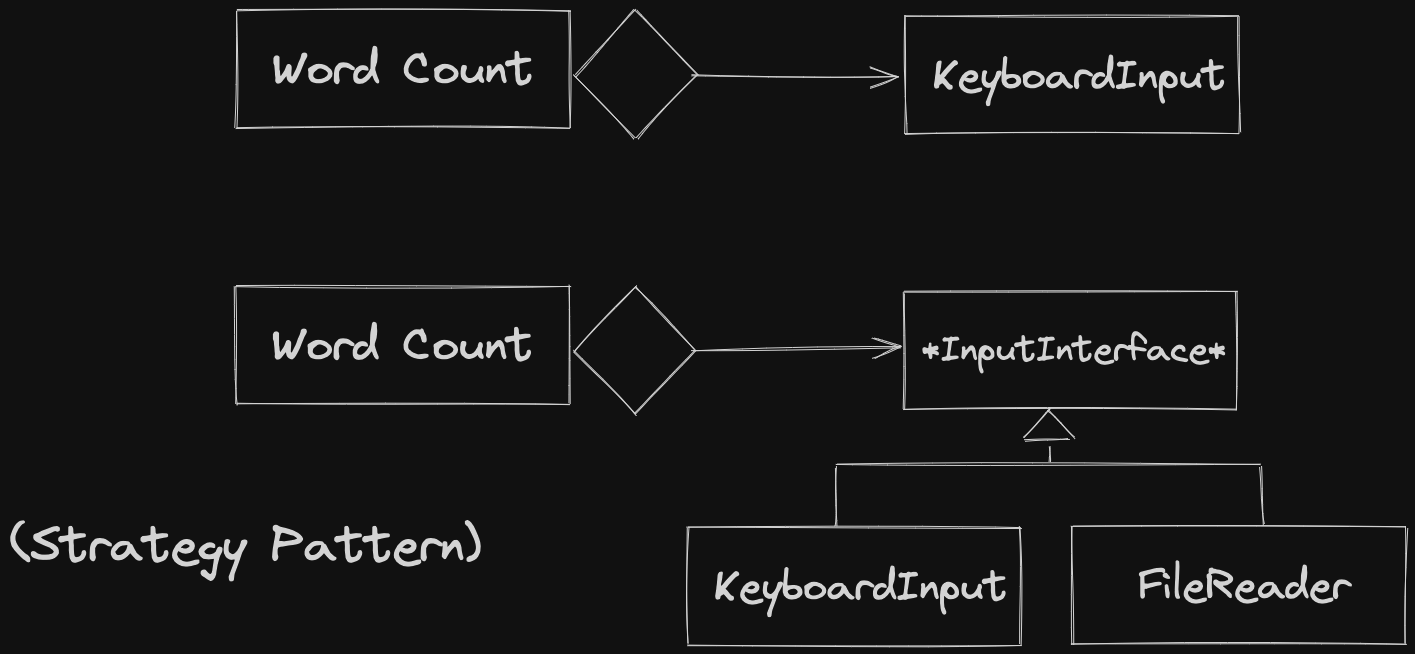
Another Example: Timer, lights/bell that goes off
Apply dependency inversion once => timer should no longer rely directly on Bell.
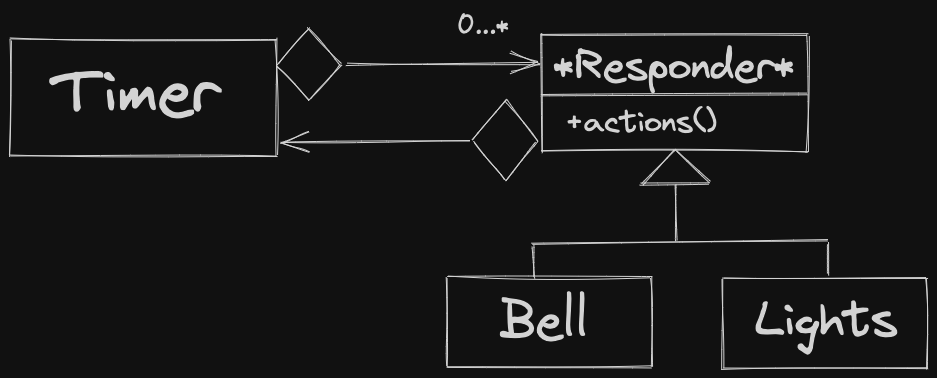
Apply dependency inversion again => Abstract Responder should not depend on the concrete timer.
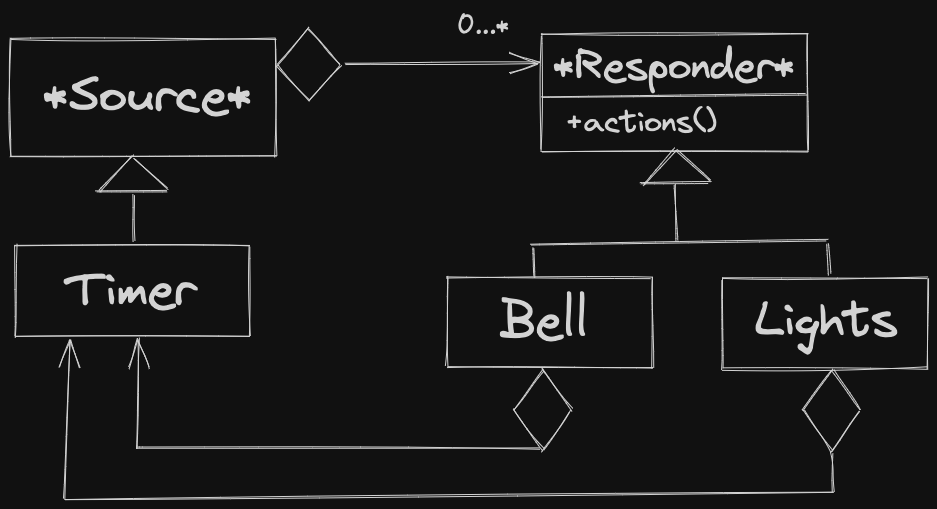
This is simply the Observer Pattern - where Sources are subjects, Responders are observers.
Could apply dependency inversion again → introduce another layer of abstraction between timer and bell / lights - but at some point, usefulness runs out. Too many layers of abstraction creates needless complexity.
What problem does Visitor Pattern solve?
“How do we write a method that depends on two polymorphic types?”
Example:
We might want different behaviours for each combination of these concrete classes.
class Weapon {
public:
virtual void strike(Enemy& e) = 0;
};We can override this in Rock and Stick, but we don’t know which enemy we’re hitting. Same problem exists in reverse if we implement it inside of Enemy.
- Notice that dynamic casting can partially fix this issue, but not completely
Solution: Visitor Pattern - combine overloading and overriding.
class Enemy {
public:
virtual void beStruckBy(weapon& w) = 0;
...
};
class Monster: public Enemy {
public:
void beStruckBy(Weapon& w) {
w.strike(*this);
}
};
class Turtle: public Enemy {
public:
void beStruckBy(Weapon& w) {
w.strike(*this);
}
};
class Weapon {
public:
virtual void strike(Monster& m) = 0;
virtual void strike(Turtle& t) = 0;
};
class Rock: public Weapon {
public:
void strike(Monster& m) override {
cout << "Rock vs. Monster" << endl;
}
void strike(Turtle& t) override {
cout << "Rock vs. Tutrtle" << endl;
}
}; // Stick looks similar
Enemy* e = ...;
Weapon* w = ...;
e->beStruckBy(*w);beStruckByis a virtual function either callingMonster::beStruckByorTurtle::beStruckBy(runtime)- Call
w.strikeon theWeapon&. Strike is virtualRock::strikeorStick::strike(runtime) - Are we calling
Rock::strike(Turtle&)orRock::strike(Monster&)? We know the type of this. If this is aTurtle*, then use theTurtleversion. If this is aMonster*, then use theMonsterversion (compile time)
Another use of the visitor pattern - add behavior and functionality to classes, without changing the classes themselves.
Example: Compiler Design
I might want to collect info about my AST.
I could add a virtual method in ASTNode, override in concrete classes.
But: lots of changes are scattered over many classes. Difficult to understand, harder to implement incrementally.
Instead: provide nodes an accept method, taking in a polymorphic AstVisitor.
class AstNode { // like Enemy
public:
virtual void accept(AstVisitor& a) = 0; // like beStruckBy.
}
class IfStatement: public AstNode {
public:
void accept(AstVisitor& a) {
a.visit(*this);
// Call accept on subnodes in our ifStatement (boolean xpression, block of statements in ifStatement)
}
};
class AstVisitor { // weapon
public:
virtual void visit(IfStatement& i) = 0;
virtual void visit(WhileStatement& w) = 0;
...
// for each AstNode
}Now, we can write different types of visitors to work on the parse tree. For example:
- String Visitor collect string literals in program, that must go in the DATA segment
- Scope Visitor match variables with associated scope
- CodeGeneration Visitor generates assembly for each given node
Solution improves cohesiveness all code for a particular visitor is located in one class. New visitor are easy to create, and can be made with 0 changes to the AST.
Lecture 21
I’m still not satisfied with this visitor pattern. Too much code!
There is going to be a lot of methods.
If we have subclasses of and subclasses of : different methods to write.
Annoying part: Boilerplate - write the following in each DerivedEnemy:
class DerivedEnemy: public Enemey {
public:
void beStruckBy(Weapon& w) {
w.strike(*this);
}
};- must be one for every single
DerivedEnemy - Cannot put it in
Enemy:
class Enemy {
public:
void beStruckBy(Weapon& w) {
w.strike(*this); // this is just an Enemy
}
};Doesn’t work - type of this is wrong. It’s not telling us what the dynamic type is.
Solution to fixing the boilerplate code: CRTP (Curiously Recurring Template Pattern)
Template our superclass with a type parameter - inherit, AND substitute the derived class type.
template<typename T> class Base {
...
};
class Derived: public Base<Derived> { // At this point, we know Derived is a class.
... // use T in Base as if had provided a forward declaration
}How do we use this to fix the boilerplate code?
template<typename T> class Enemy {
public:
void beStruckBy() {
w.strike(*static_cast<T*>(this));
}
};
class Monster: public Enemy<Monster> {...};
class Turtle: public Enemy<Turtle> {...};This sort of works
Weapon* w = ...;
Turtle t{...};
t.beStruckBy(*w); // Calls Enemy<Turtle>::beStruckByCast this from type Enemy<Turtle>* to Turtle* allows us to override into Rock::Strike(Turtle&) and Stick::Strike(Turtle&).
Issue: Now, we have different superclasses for each Enemy
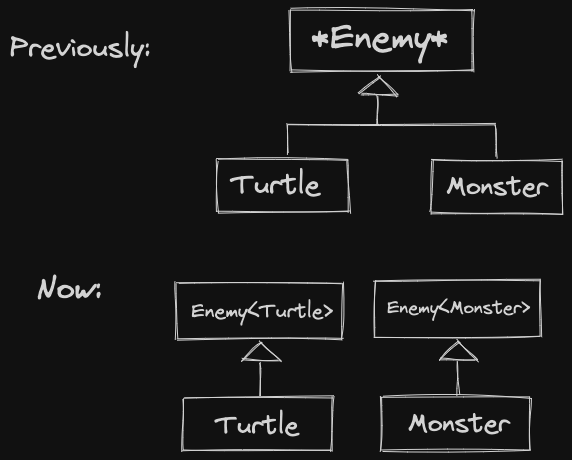
Because Enemy<Turtle> and Enemy<Monster> are different classes: can no longer use Enemys polymorphically - no vector<Enemy*> allowed!
Solution: Add another layer of inheritance.
class Enemy {
public:
virtual void beStruckBy(Weapon& w) = 0;
virtual ~Enemy() {}
};
template<typename T> class EnemyBeStruck: public Enemy {
public:
void beStruckBy(Weapon& w) override {
w.strike(*static_cast<T*>(this));
}
virtual ~EnemyBeStruck() = 0;
}
template<typename T> EnemyBeStruck<T>::~EnemyBeStruck<T>() {}
class Turtle: public EnemyBeStruck<Turtle> {...}
class Monster: public EnemyBeStruck<Monster> {...}Now, we have a public interface by which all our concrete enemies follow: can all beStruckBy weapons. We use the virtual method in Enemy to resolve beStruckBy to either EnemyBeStruck<Turtle> or EnemyByStruck<Monster> . Then just static_cast to T* - and we’re good.
Weapon* w = ...;
Enemy* e = new Turtle{...} / new Monster{...};
e->beSstruckBy(*w);Another problem CRTP can solve: polymorphic cloning.
Recall abstract books:
Say I have:
AbstractBook* b = ...;I want a deep copy of whatever b points to. I cannot just do this:
AbstractBook* b2 = new AbstractBook{*b};This attempts to create an AbstractBook by invoking its constructor. Wrong for 2 reasons:
AbstractBookis abstract, cannot instantiate those objects- Ignoring what we’re actually pointing at, we actually want to invoke a constructor that depends on the dynamic type of
b
We can provide a virtual clone method for the purpose of solving this:
class AbstractBook {
public:
virtual AbstractBook* clone() = 0;
virtual ~AbstractBook() {};
};
class Text: public AbstractBook {
public:
Text* clone() override {
return new Text{title, author, length, topic};
}
};
// Comic and NormalBook are similar
AbstractBook* b = ...;
AbstractBook* b2 = b->clone();Instead use the copy ctor in each of our clone methods to simplify the implementation.
class Text: public AbstractBook {
public:
Text* clone() override {
return new Text{*this};
}
};Exact same code in MermaidBook and Comic - just the type of this and the type of ctor which is changing. Once again, we can use CRTP.
class AbstractBook {
public:
virtual AbstractBook* clone() = 0;
virtual ~AbstractBook() {};
};
template<typename T> class BookClonable: public AbstractBook {
public:
T* clone() override {
return new T{*static_cast<T*>(this)};
}
virtual ~BookClonable() = 0;
};
template<typename T>
BookClonable<T>::~BookClonable<T>() {};
class Text: public BookClonable<Text> {...};
class Comic: public BookClonable<Comic> {...};
AbstractBook* b = new Text{...} / new Comic {...};
AbstractBook* b2= b->clone();b->clone is virtual, so if b points at a Comic, we call BookClonable<Comic>::clone - static_cast this into a Comic* and invoke the Comic copy constructor with the Comic&.
Provided for all subclasses - reduces boilerplate code.
Command Pattern About using objects to encapsulate behavior of some “action” with a system.
Example: Consider writing an IDE, using MVC - we might have model/controller relationship where controller calls model methods, like:
Model::insert TextModel::copyModel::pasteModel::changeSyntaxHighlighting
This is a decent design - but it doesn’t allow for some features we might desire:
- Macros - replaying sequences of instructions
- Undo / redo
Command pattern: Instead of manipulating the model directly - pass commands to an invoker
Command object has whatever information it needs to perform its given action - maybe model, maybe subjects within the model
- Controller would create command objects, supply with info they need
- Sends abstract commands to the
Invokerfor processing Invokercalls each action method to execute the command
Invoker can maintain additional state - stack of commands for undo / redo, or mapping of a macro keyword to a list of commands.
Lecture 22
Recall: We saw that reasoning about programs with exceptions is tricky.
void f() {
int* p = new int{247};
g();
delete p; // memory is leaked iff g throws
}We can be more specific about how safe our program is given an exception is thrown. 4 levels of exception safety:
- No exception safety - If an exception is thrown - no guarantees about program state - object has invalid memory, memory is leaked, program crashes.
- Basic guarantee - if an exception is thrown - program is in a valid, but unspecified state. Ex: Class invariants are maintained, no memory is leaked.
- Strong guarantee - If an exception is thrown, the program reverts back to its state before the method was called. Ex:
vector::emplace_back- Either it succeeds, or if exception is thrown, vector is in its prior state
- Nothrow guarantee - exceptions are never propagated outside of the function call - always does its job. Ex:
vector::sizegivesnothrowguarantee, always returns size of vector without fail.
class A{...};
class B{...};
class C {
A a;
B b;
public:
void f() {
a.g();
b.h();
};
}What is the exception safety of f?
A::g and B::h both provide the strong guarantee.
f - only satisfies the basic guarantee.
If a.g() throws, then because it provides strong guarantee - it’s as if it was never called
- when exception propagates from
f,fhas not done anything
If b.h() throws - it provides the strong guarantee, so it does undo any of its effects. BUT: it has no knowledge that a.g() ran just prior. As a result, when exception propagates from f, the effects of a.g() remain in place.
Program is in a valid yet unspecified state basic guarantee
Right now, there may be effects of a.g() that are impossible to undo writing to a file, printing to the screen, sending a network request.
For simplicity, we’ll assume A::g and B::h have only local side effects (i.e. only the a and b objects and any associated memory may change).
Now, how may we try to rewrite f to achieve the strong guarantee?
Idea: Use Copy-and-Swap Idiom, only work on temporary objects rather than real ones.
class C {
A a;
B b;
public:
void f() {
A aTemp{a};
B bTemp{b};
aTemp.g();
bTemp.h();
a = aTemp; // copy assignment operator (could throw)
b = bTemp;
}
}If aTemp.g() or bTemp.h() throw - no changes are made to the C object, it’s as if f was never called.
This is unfortunately, still the basic guarantee. Because, if b = bTemp throws, we propagate an exception having modified a.
What we really need for this is a non-throwing swap or assignment. Assigning a pointer will never throw. One possible solution: PImpl Idiom, “pointer to implementation”
struct CImpl { // "Impl" class has the fields
A a;
B b;
};
class C {
unique_ptr<CImpl> pImpl;
public:
void f() {
unique_ptr<CImpl> temp = make_unique<CImpl>(*pImpl);
temp->a.g();
temp->b.h();
std::swap(temp, pImpl); // guaranteed nothrow
}
};This is the strong guarantee - if a.g() or b.h() throw - all work is done on temp, so we’re fine.
Otherwise, swap will always succeed f will do its job.
PImpl Idiom can also be used in some scenarios for reducing compilation dependencies.
typically:
C.h
class C {
A a; // If any of the private fields change, anbody who #include "C.h" must recompile
B b;
};On the other hand:
CImpl.h
struct CImpl {
A a;
B b;
};C.h
class CImpl;
class C {
unique_ptr<CImpl> pImpl;
...
};Now, if cImpl changes only C.cc must recompile. Because we only use a forward declaration in C.h no recompilation.
Finally - we could make CImpl a polymorphic class - swap out implementations at runtime - the Bridge Pattern.
Back to exception safety - vector::emplace_back. Gives us the strong guarantee. How?
Easy case: No resize, just put the object in the array. When resizing:
- allocate a new, larger array
- Invoke array copy constructor to copy objects of type T to new array
- If copy constructor throws: delete the new array, old array is left intact.
- Then delete old array, and set array ptr to new array (nothrow).
Complaint: This is a lot of copies when all I really want was to resize my array.
Better, would be to move:
- Allocate a new array
- Move objects from the old array to the new array
- If a move throws, move all our objects back from new array to old array, delete new array
- Delete old array, set pointer to new array
Problem: If move throws once, it might also when moving objects back. Once we’ve modified our old array, no guarantee we can restore it.
Solution: If move constructor is declared as “noexcept”, then emplace_back will perform moves. Otherwise, it will copy over every item, and do this try-catch block to delete old items if necessary.
If possible, moves and swaps should provide the nothrow guarantee - and you should make this explicit to the compiler via the noexcept tag.
class MyClass {
public:
MyClass(MyClass&& other) noexcept {...}
MyClass operator=(MyClass&& other) noexcept {...}
};If you know a function will never propagate an exception - declare it noexcept to facilitate optimization.
Moves and swaps at the minimum should be noexcept.
Lecture 23
Most CPUs in the modern day have more than one core.
This can sometimes allow extraction of extra efficiency.
Example: Matrix Multiplication
Typically, compute entries in order:
In a multithreaded program: Create separate threads to perform the computations simulataneously.
void multiplyRow(int row, const vector<vector<int>>& A, const vector<int>& x, vector<int>& output) {
output[row] = 0;
for (int i=0;i<A[row].size();i++) {
output[row] += x[i] . A[row][i];
}
}This allows us to multiply each row for our product .
vector<vector<int>> A {{1,2,3}, {4,5,6}, {7,8,9}};
vector<int> x {10,11,12};
vector<int> y{0,0,0};
vector<thread*> threads;
for (int i=0;i<A.size();i++) {
threads.push_back(new thread{multiplyRow, i, std::cref(A), std::cref(x), stdd::ref(y)})
}
for (thread* t: threads) {
t->join(); // waits, stalls the program until t has finished running.
delete t;
}
// by this point, all threads have completed - we can now use yWhy do we need ref/cref, the thread ctor implictly copies / moves its parameters.
cref, ref: create reference-wrapper object types, which can be copied / moved.
- distributed the workload. Each thread works independently on a separate part of the problem.
This is an example of an “embarrassingly parallelizable” problem.
What about synchronization? First: Compute Then compute gives us
We need to compute in entirety, before we may compute
Simply:
- Spawn threads for , join them.
- Spawn new threads for , join them
But: creating threads is expensive. What if we reuse the same threads?
Let’s do a barrier example: 2 functions - f1 and f2: both must complete phase 1, then they can proceed to phase 2.
bool t1Ready = false, t2Ready = false;
void f1() {
cout << "Thread 1 Phase 1" << endl;
t1Ready = true;
while (!t2Ready) {}
cout << "Thread 1 Phase 2" << endl;
}
void f2() {
cout << "Thread2 Phase 1" << endl;
t2Ready = true;
while (!t1Ready) {}
cout << "Thread 2 Phase 2" << endl;
}Why are the outputs different?
You should run this for yourself, sometimes the output will be differing. This is because the
<<is actually a function call. Since the threads run simultaneously, you actually don’t have the guarantee that an entire line runs alone and prints together (because there are actually two function calls in that single line).
is there a solution? Yes, use \n instead of endl.
Use std::atomic<bool> to prevent incorrect compiler optimizations with multithreaded code.
Conclusion, what was CS247 about?
This is not actually a course about C++. Purpose?
High-level Thinking:
- How well do my programs accommodate changes?
- How do I balance simplicity vs. abstraction?
- Where is abstraction useful, and where is it cumbersome?
Low-Level Thinking:
- What is the compiler doing?
- What are the efficiency tradeoffs in abstractions.
- Do I have a clear understanding of what my language compiles.
Learning more programming paradigms in detail will make you a better programmer.